Introduction
The DBOD service maintains a web interface allowing "database on demand" users to carry out ordinary tasks without intervention of the administrators.
It is with a view to ergonomy, but above all to modularity and scalability, that a complete redesign of this application has been initiated. Node.js, which appeared in 2009, as well as its eco-system and MVC front-end frameworks such as Angular are major advances in the Web development landscape. The migration to these technologies is undoubtedly a very profitable act for a database management interface like ours, which we want to see lasting over time while constraining as little as possible the future technological choices concerning its operational back-end.
The precedent Web application based on the ZK framework was presented as follows:

The same page will look like this:

In this blog post I would like to give additional information about the technologies implemented in this project (in the part that concerns me, i.e. rather close to the front-end), referring you to my report for more details regarding the specific features implemented (the Web content itself).
First of all, the following scheme constitutes a summary of the architecture on which the new database on demand system is built:
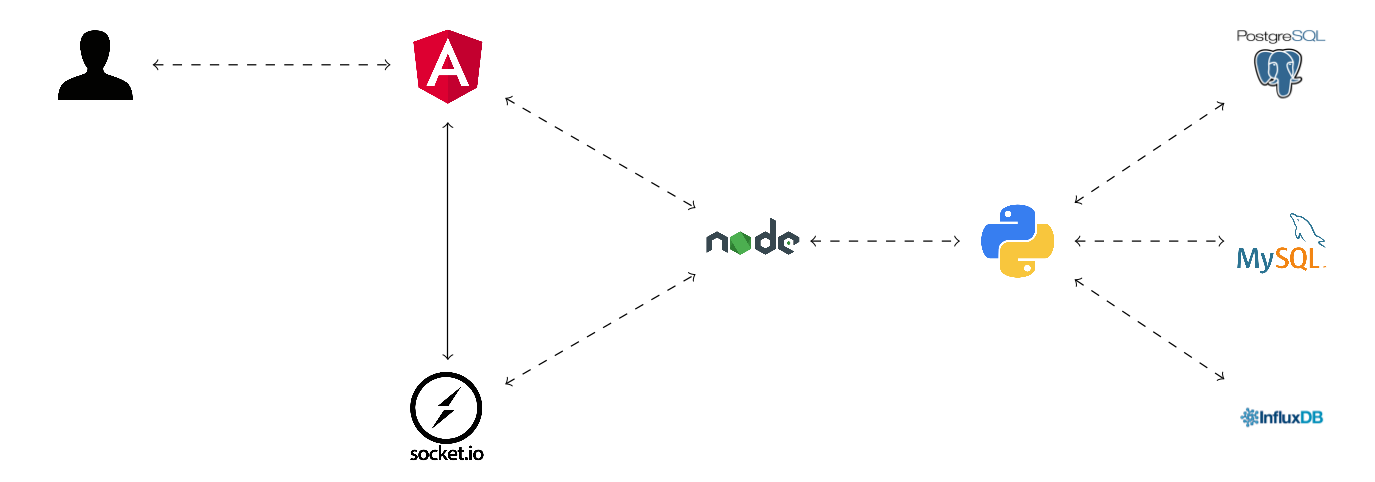
Node.js
I'll just quote Wikipedia:
"Node.js is an open-source, cross-platform JavaScript run-time environment that executes JavaScript code outside of a browser. [...] Node.js represents a "JavaScript everywhere" paradigm, unifying web application development around a single programming language, rather than different languages for server side and client side scripts. [...] Node.js has an event-driven architecture capable of asynchronous I/O. These design choices aim to optimize throughput and scalability in web applications with many input/output operations, as well as for real-time Web applications"
Then, further on:
"Node.js brings event-driven programming to web servers, enabling development of fast web servers in JavaScript. Developers can create highly scalable servers without using threading, by using a simplified model of event-driven programming that uses callbacks to signal the completion of a task. Node.js connects the ease of a scripting language (JavaScript) with the power of Unix network programming. Node.js was built on the Google V8 JavaScript engine since it was open-sourced under the BSD license. It is extremely fast and proficient with internet fundamentals such as HTTP, DNS, TCP. Also, JavaScript was a well-known language, making Node.js immediately accessible to the entire web development community"
Finally:
"There are thousands of open-source libraries for Node.js, most of them hosted on the npm website. The open-source community has developed web frameworks to accelerate the development of applications. Such frameworks include Connect, Express.js, Socket.IO, Feathers.js, Koa.js, Hapi.js, Sails.js, Meteor, Derby, and many others."
To summarize, node.js roughly meets the same need as Apache - basically, to provide a context for developing an HTTP server - but by executing Javascript code (language historically dedicated to client-side programming) rather than PHP or Python. This is already a contribution in terms of universalism, since only one language can be used to program a complex website entirely.
In addition, node.js manages asynchronous programming particularly well, natively (which is not the case of PHP for example). The idea is: when calling a function that will take some time (an HTTP request for example), the execution of the rest of the code keeps going. Thus, as soon as the HTTP response is obtained, a callback function is triggered which interrupts for a short time the execution of the current code to manage this new data.
http.get('http://host.cern.ch/path', (res) => {
let rawData = '';
res.on('data', (chunk) => { rawData += chunk; });
console.log('Got response: '+rawData);
}).on('error', (err) => {
console.error('Got error: '+err.message);
});
Promises
This approach brings some complications. For example, if you want to chain HTTP requests you can quickly get into a situation where the code matches like a callback pyramid:
http.get('http://host.cern.ch/path1', (res1) => {
http.get('http://host.cern.ch/path2', (res2) => {
http.get('http://host.cern.ch/path3', (res3) => {
let rawData = '';
res3.on('data', (chunk) => { rawData += chunk; });
console.log('Got response: '+rawData);
});
});
});
In the same way, how to chain asynchronous actions within a for loop (which is not a purely theoretical case: I had to manage one in the context of the website that is the subject of this post)? In these situations, another concept will be used: that of "promise".
var promiseHttp = (data) => {
return new Promise( (resolve, reject) => {
http.get('http://host.cern.ch/path'+data.i, (res) => {
resolve({'res': res, 'i': data.i++});
});
}).on('error', (err) => {
reject(err);
});
};
var promise = Promise.resolve({'res': null, 'i': 0});
for(var i=1; i<=3; i++) {
promise = promise.then(promiseHttp);
}
promise = promise.then( (data) => {
let rawData = '';
data.res.on('data', (chunk) => { rawData += chunk; });
console.log('Got response: '+rawData);
}).catch( (err) => {
console.error('Got error: '+err.message);
});
First of all, a promise is defined. The "resolve" function is called if it is executed correctly, "reject" otherwise. After that, we create a new empty but resolved promise with Promise.resolve(). Then, we chain the promises within a for loop using the keyword "then", until the data that interests us (the third answer) is obtained, and finally we chain with a last function (which can be a Promise obviously) dedicated to the processing of this data.
What happens here is: if one of the HTTP requests fails, then "reject" will be called, breaking the promise chain and triggers "catch". On the other hand, if "resolve" is called, its parameter is transmitted to the next promise via "then". This is how promises work.
The Promise object being intrinsic to Javascript, can be used on both the client and server sides. I must also mention the "observables", which are another programming concept specific to asynchronous programming, which roughly meet the same needs as the promises but at a higher level.
socket.io
Here is how Tim Berners-Lee would have sent an HTTP request from client to server (HTML2) in his office on the second floor of building 31:
<form action="formsent.html"> <input type="text" name="field_1"><br/> <input type="text" name="field_2"><br/> <input type="submit" value="Submit"/> </form>
When he clicks on the submit button, values of field1 and field2 are sent to server, thus a new page is entirely generated in response and loaded in the browser instead of the current one.
Then, in the 2000’s was invented the Asynchronous Javascript & XML (AJAX) technology:
<form> <input type="text" #field_1><br/> <input type="text" #field_2"><br/> <input value="Submit" (onclick)="sendReq()"/> </form>
var sendReq = function() {
var xhr = new XMLHttpRequest();
xhr.open("POST", '/server', true);
xhr.send("value1="+document.querySelector("#field1")
+"&value2="+document.querySelector("#field2"));
xhr.addEventListener("load", function(event) {
console.log('Status:'+xhr.status)
});
}
You press the button, the sendReq function in triggered and data is sent to server without need to refresh webpage. Furthermore, as soon as the answer is obtained, the load event is called.
It is an asynchronous behavior such as those we were discussing earlier, no doubt. But there is still one issue: AJAX is not intended to allow the server to solicit the client. That is to say, a chat using only AJAX for example, would have no alternative but to leave a Refresh button on the screen on which the user would have to click to check for the absence of new message.
Of course, on social networks we receive our messages as they are posted, without any prior action from the user. The reason is that the modern Web makes great use of websockets.

Unlike AJAX, websocket should be seen as a substitute for HTTP requests (or an emulation of them) and not as another way to perform them. It is therefore a two-way (!) communication channel that is permanently installed between a page opened in the browser and the server. Under node.js, we use the socket.io package:
Client side:
io.on('connection', (socket) => {
socket.emit('request',{value1: ..., value2: ...});
socket.on('reply', () => {
/* */
});
});
Server side:
io.on('connection', (socket) => {
socket.on('request', (data) => {
/* */
socket.emit('reply',...);
});
});
Thus, everything is perfectly asynchronous and symmetrical, and web developers are happy. Although you are on another tab, you are informed in real time that you have been tagged in a questionable Meme on Facebook; isn't that great?
JSON Web Token
Due to a particularity of our Node.js code, the part dedicated to the socket is completely separated from the part related to Authentication management. For this reason, we had issues implementing a session system common to both HTTP routes and the socket. The solution found is based on JSON Web Tokens that use a hash algorithm to sign a message.
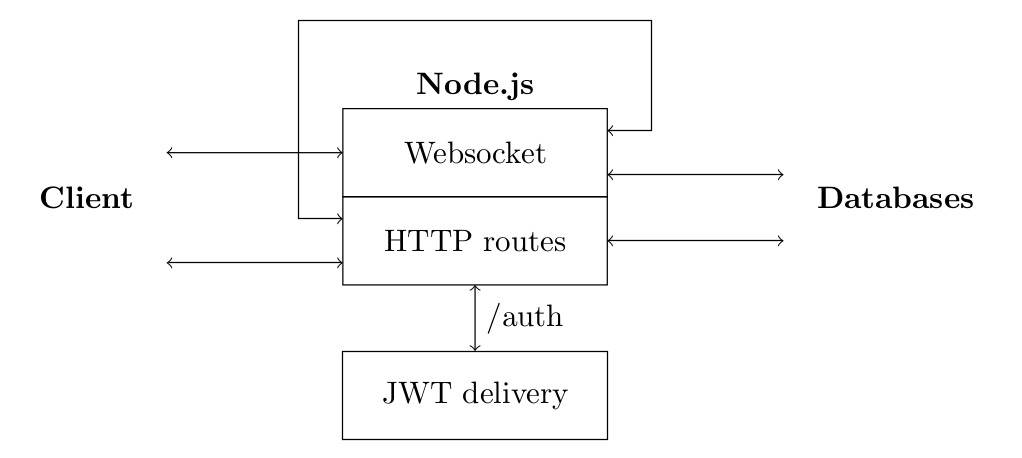
The idea is not to protect information, but to authenticate it. In principle, a potential hacker can decrypt a token that is not intended for him (although this is not the case for HTTPS communication), but that's not the point.
Unlike the certificates and session IDs that are commonly used, this token contains all the session information for us. What JSON Web Tokens guarantee, is the validity of this information, insofar as it was indeed the server that emitted it and not someone who would like to benefit of additional privileges.
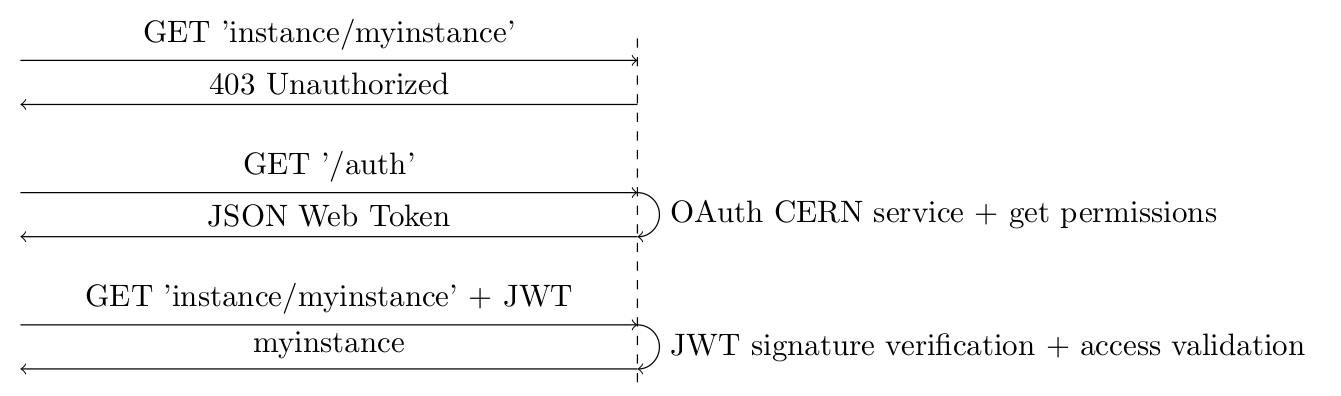
The client authenticates, the server responds with a token, encrypted with a private key that it has in memory. This token contains all the session information, which Angular uses at its discretion to generate the view. If he wishes to make a request, he must attach the token to it. In server side, once the origin and integrity of the token has been verified, its content is used to give or deny the request without having to access session data stored somewhere.
function routesValidate(req,auth) {
switch(req.url.split('?')[0].split('/')[1]) {
case('instance'):
// If user is admin, or owns the instance and is not doing a POST or DELETE request on anything else than 'attribute/backup'
return auth.admin || (req.url.split('?')[0].split('/')[2]==undefined || auth.instances.includes(req.url.split('?')[0].split('/')[2])) && (req.method!='POST' && req.method!='DELETE' || req.url.split('?')[0].split('/')[3]=='attribute' && req.url.split('?')[0].split('/')[4]=='backup');
break;
case('rundeck'):
// If user is admin, or owns the instance
return auth.admin || auth.instances.includes(req.url.split('?')[0].split('/')[4]);
break;
// Additional routes access restriction come here
default:
return true;
}
}
try {
var auth = jwt.verify(req.headers['jwt-session'], 'private-key');
if(routesValidate(req,auth)) {
return auth;
}
else {
console.trace('Unauthorized');
}
} catch(err) {
console.trace('JWT Verify error!',err);
}
The other interest is to simplify the subsequent implementation of a secure API, reducing the entire authentication process in the delivery and handling of a signed token containing all the information required to take permission into account.
Conclusion
There are other technical aspects to consider when reviewing the technologies used in this website: the MVC pattern applied to the front end via Angular (and applicable to the back-end if it becomes more complex), the Angular Material library which provides the UI components, other back-end elements, etc. Nevertheless, through this blog post I simply wanted to give the key theoretical notions that allow you to feel how the whole thing works.
Thanks to the IT-DB department for having welcome me as a Summer Student.