Authored By: Nazerke Seidan, Emil Kleszcz, Zbigniew Baranowski
Published By: CERN IT-DB-SAS
In this post, we will dive into the evaluation of the Erasure Coding feature of Hadoop 3 that I worked on this summer as a CERN Openlab intern. The evaluation has been performed on one of the Hadoop bare-metal clusters provided by the central Hadoop service at the CERN IT department [6].
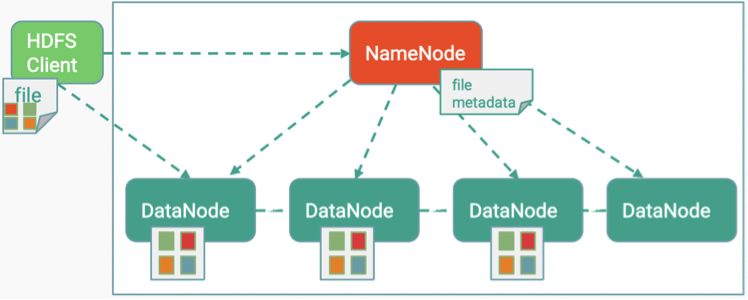
Let us begin with the Hadoop ecosystem which is essentially a distributed computing platform for Big Data solutions by comprising autonomous components such as HDFS, Hadoop MapReduce, Spark, YARN, etc. HDFS is a Hadoop Distributed File System for data storage that is different from a standard file system in a way that HDFS stores data in blocks distributed on multiple machines (can be hundreds) to provide scalability and is considered to be highly fault-tolerant. In other words, it can resist up to certain machine failures in the system. At CERN, the current HDFS configuration supports a 3x replication scheme for data redundancy and availability. For example, when a client writes a file to HDFS, the file is stored in blocks (256MB). The blocks will be replicated twice and distributed over the DataNodes (DNs) on the cluster. This approach works like RAID1 (Redundant Array of Inexpensive Disks) where data is mirrored without additional striping. The following figure illustrates the HDFS 3x replication strategy:
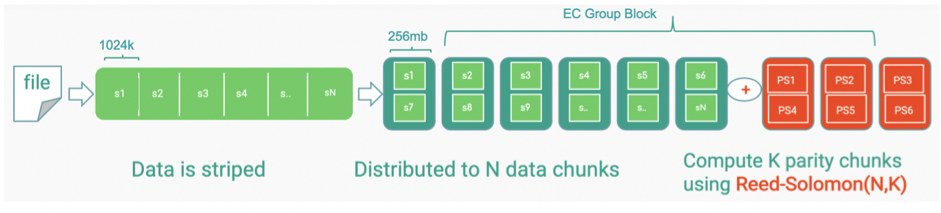
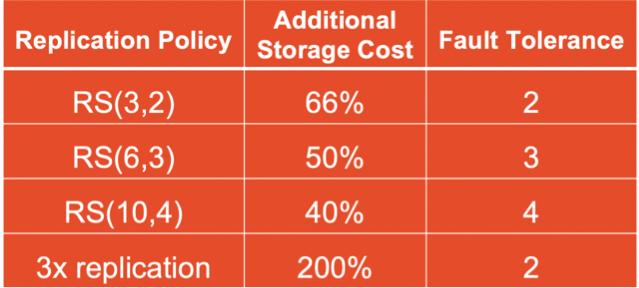
In theory, EC decreases the storage cost by approximately 50% without compromising the core HDFS abilities (fault tolerance, scalability and performance), but practically this might not be exactly true. Thus we have done some performance tests for EC in order to inspect how EC performs compared to 3x replication. We mainly focused on the measurement of raw storage and analytics performances of EC. We evaluated the performance of write/read operations to/from HDFS on small datasets. For the tests, we leveraged the TPC-DS benchmark on Spark SQL queries of 10GB, 100GB and 1TB datasets in Parquet and JSON data file formats. For this performance testing, we configured a cluster which has 16 bare-metal machines: 14 DataNodes (DNs), 2 NameNodes (NNs), 512 GB RAM per node, 16 physical CPU cores per node, 48 HDDs drives per node each 5.5 TB and 2 SSDs 1TB each for local file system and fast data spilling/in-memory operations. For the TPC-DS benchmarking, we used the following configuration chosen arbitrarily based on some pre-tests: 84 executors, 48GB executor memory, 4 executor cores.
In the next paragraphs, we are going to see a few evaluations results of EC.
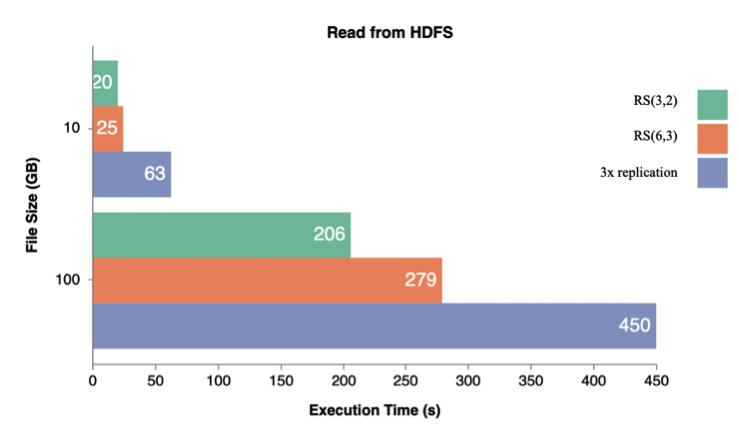
The first test demonstrates how much storage space physically is used when storing multiple files of various sizes. The graph below emphasizes the storage overhead on 3 different EC and 3x replication policies. On the y-axis 100, 500 and 1000 MB file sizes are shown, while on the x-axis the physical storage costs are given:
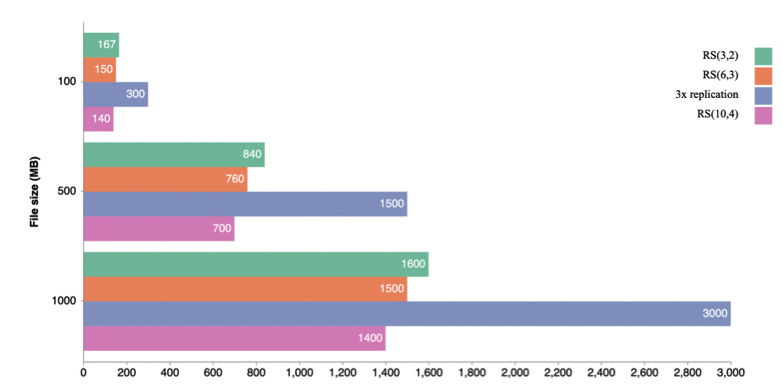
As you can see from the graph that the EC RS policy has almost 60% lower cost than 3x replication strategy.
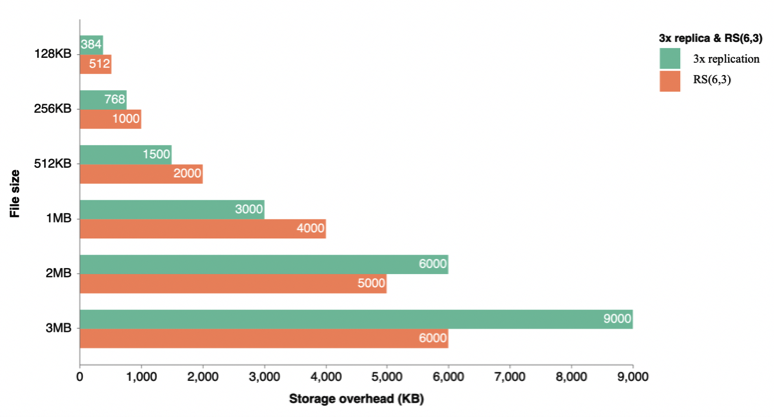
If we reduce the data file size, the EC will not perform efficiently. You may claim that Hadoop is not for storing small data files. But there might be a use case that the client writes small-sized files to HDFS at least periodically. We have an example of such a system for collecting logs from smart sensors in the Large Hadron Collider (LHC) experiment at CERN in an IoT-like environment. According to our evaluation results, if the file size is smaller than the stripe cell size, erasure-coded data occupies more space than 3x replication. The graph of the evaluation results for this use case is the following:
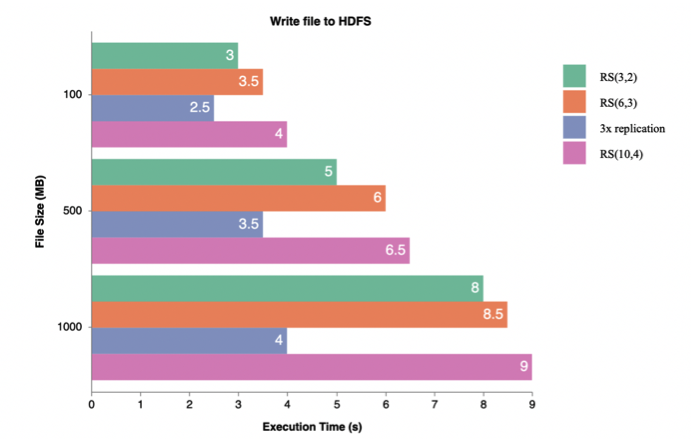
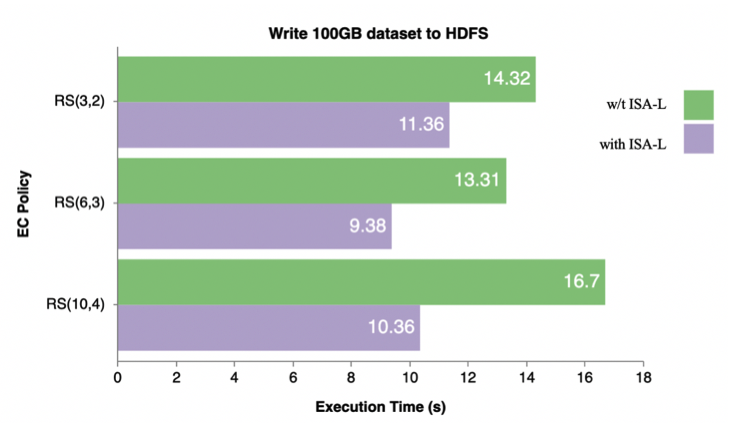
Furthermore, we used Intel’s ISA-L library to improve the performance of write operations on EC. ISA-L is a set of optimized low-level methods aiming for storage applications. Thanks to ISA-L library we obtained approximately 30% better performance result:
TPC-DS benchmark test as part of analytics performance plays a crucial role in data processing engines like Spark, Hive and etc. We generated 100GB and 1TB datasets in Parquet, JSON data file formats. Afterwards, we run the benchmark on these generated datasets using the Spark shell. Once we finished running benchmarks, we extracted the results by taking the average of all queries’ execution time.
There were 99 SQL-based queries in total. We run all these 99 SQL queries with 3 iterations in order to obtain accurate mean results and avoid hardware hiccups in Parquet and JSON formats accordingly.
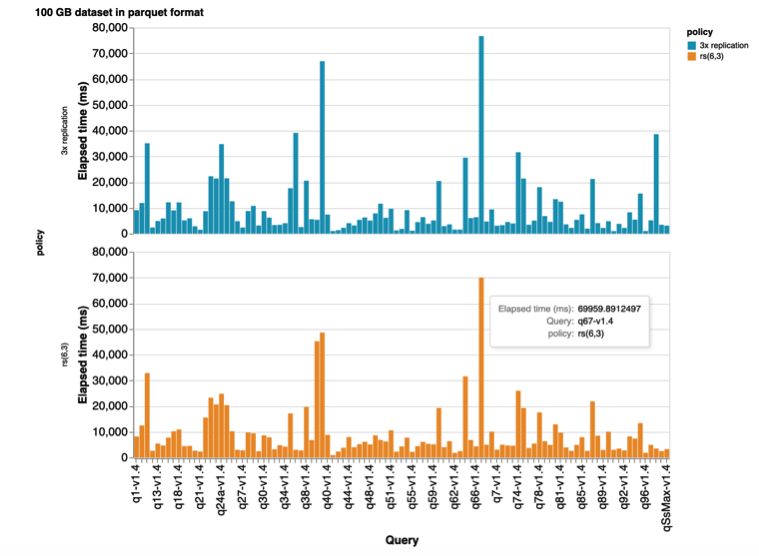
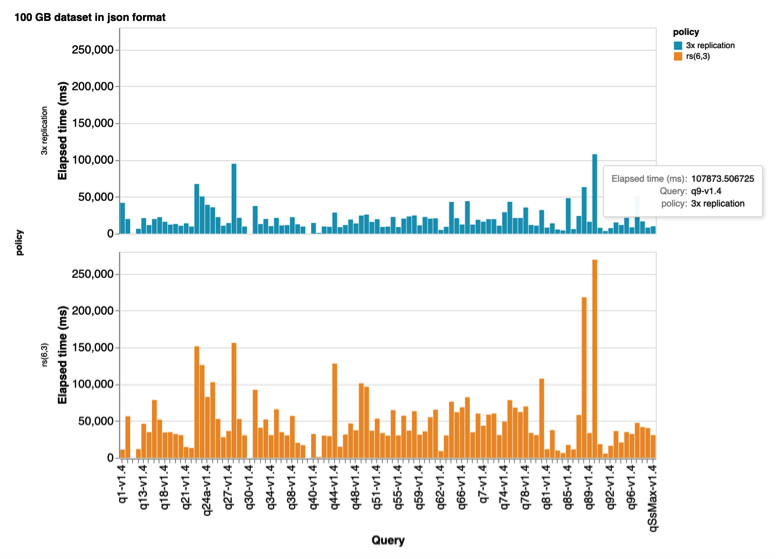
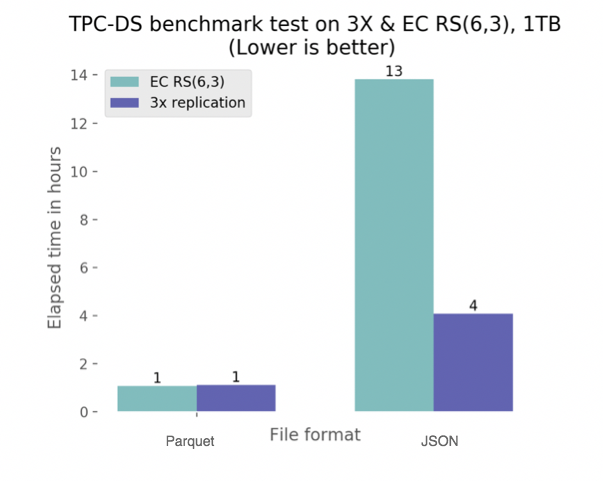
Therefore, from this experiment, we can conclude that data file formats without an optimized organization for analytic-like access (e.g. text-based formats – JSON, CSV) should be avoided for analytic processing with EC policies at all. Otherwise remote full scanning of terabytes of data may lead to saturation of the entire cluster network. This may affect also other services in the data center which are connected to the same switches but are in different racks.
To sum up, EC gives an advantage in storage savings and it can be applied to directories where cold data is stored. EC does not compromise analytics performance on smart, columnar stored formats data supports efficient filter pushdowns (Parquet, Orc, etc), however, it offers flexible configuration - can be selectively deployed on datasets as per directory. Since the tests proved that EC in HDP3 is production-ready and archived performances on the EC encoded data are satisfactory we are looking forward to introducing the EC for some cold datasets in the production clusters at CERN. We are also looking forward to further development of this feature by the whole Hadoop community.
Acknowledgments:
I would like to thank especially to my supervisors, Emil Kleszcz, and Zbigniew Baranowski for their constant support of my efforts.
I am deeply grateful to CERN Openlab program organizers for the chance to work at CERN.
I am also thankful to CERN IT-DB group for their advice and suggestions.
I am indebted to Rakesh Radhakrishnan, Sr. Software Engineer, Hadoop PMC Member, Intel Corp. for his invaluable support in a better understanding of Erasure Coding.
References:
[1] TPC-DS benchmarking:
https://github.com/tr0k/Miscellaneous/blob/master/Spark_Notes/Spark_Misc_Info.md
[3] Intel's ISA-L library:
https://github.com/intel/isa-l
[3] HDFS Erasure Coding in Production:
https://blog.cloudera.com/hdfs-erasure-coding-in-production/
[4] CERN Openlab lightning talk:
https://cds.cern.ch/record/2687101
[5] Reed-Salomon error correction algorithm
https://en.wikipedia.org/wiki/Reed%E2%80%93Solomon_error_correction
[6] Evolution of the Hadoop Platform and Ecosystem for High Energy Physics
https://www.epj-conferences.org/articles/epjconf/abs/2019/19/epjconf_chep2018_04058/epjconf_chep2018_04058.html