Topic: This blog post is about kernel stack profiling and visualization with flame graphs.
Context: Stack profiling and flame graphs are very useful tools and techniques for troubleshooting and investigating workloads at the OS-level and understand which code path take most of the execution time. You can find extensive material and examples of flame graphs in Brendan Gregg's website and blog. A few additional examples of using stack tracing and flame graphs for investigating Oracle are: "Flame Graphs for Oracle" and "Oracle Optimizer Investigated with Flame Graphs".
Flame graphs are often used to visualize and analyze stack traces for CPU-bound processes. Perf has proven to be a very good tool to capture such traces in Linux. With perf you can collect stack backtraces of the running processes with little overhead. However this does not cover the cases when the process under investigation is off-CPU (for example sleeping and/or waiting for an I/O operation to finish). This topic has also been addressed by Brendan Gregg in his blog, with off-CPU flame graphs. However data collection for the case of off-CPU stack traces seems to be still an area of active investigation, especially for Linux. This post addresses the case of collecting kernel stack data for flame graph visualization in the case of processes that spend a large fraction of their time off-CPU and/or in system calls.
What's new: In this blog you can find a description of a basic technique for sampling kernel stacks and a script to automate the process. The script gathers kernel stack traces and process status by sampling the /proc filesystem. This is intended for investigations of processes in Linux that spend a significant part of their elapsed time off CPU (for example in status S, sleep, or D, disk sleep).
The main engine of the script is a simple loop reading /proc/pid/stack. I have first heard of this idea in Tanel Poder's blog. A similar concept is also used in the poor man's profiler. Just to illustrate how simple the method is, here is the main data collection part of kstacksampler.sh:
for x in $(seq 1 $iterations); do
cat /proc/$pid/stack # get kernel stack trace
done
Notes and limitations: The script kstacksampler.sh is quite basic, to be taken as a proof of concept and study material. The overhead and potential side effects of using it are expected to be minimal for most of the systems, so most likely it is safe to use it in production. The use of shell for profiling does not allow for high frequency sampling, typically you should start experimenting with 10-20 Hz. Processes that are busy with CPU usage should rather be traced using perf and on-CPU flame graph techniques. The script currently only traces one process at a time (although it could be adapted to trace multiple pids). The script does not trace threads (although it can be modified to trace tids from /proc/pid/task/tid/stack). The script does not provide userspace traces. The script samples both the process kernel stack and status (running, sleeping, etc). A simple editing of the script can disable this feature if not needed. Note that in Linux the process status "running" refers to both running and runnable (in run queue) processes.
Example 1: Investigation of a workload with a network bottleneck.
Preliminary info:
The case is of a database session retrieving data over a slow network. A simple statement "SELECT * FROM LARGETABLE;" is used to generate the workload. When examining the database process (on the DB server side) it shows little usage of CPU. This can be investigated for example using pidstat (RHEL/EL 6.7 was used for this test).
[root@MYDB]# pidstat -p 9124 1 10
Linux 2.6.32-573.7.1.el6.x86_64 (MYDB) 10/22/2015 _x86_64_ (4 CPU)
10:10:28 PM PID %usr %system %guest %CPU CPU Command
10:10:29 PM 9124 0.00 4.00 0.00 4.00 0 oracle_9124_orc
10:10:30 PM 9124 4.85 4.85 0.00 9.71 2 oracle_9124_orc
10:10:31 PM 9124 1.00 2.00 0.00 3.00 2 oracle_9124_orc
You can also use Oracle instrumentation to investigate the process and find that it is mostly idle. In particular V$ views such as V$SESSION, V$SESSION_LONGOPS, V$ACTIVE_SESSION_HISTORY are some of the views that can be used, or rather their graphical counterpart using OEM.
Stack Tracing:
You can now try the script kstacksampler.sh and build a flame graph with its output to further the investigation. In the following the task is divided in two steps. The first step is data collection with kstacksampler.sh, with some additional data filtering with grep and sed. The second step integrates with the FlameGraph toolset. In particular stackcollapse-stap.pl folds the stack and flamegraph.pl builds the flame graph (see Figure 1).
Step1: stack sampling
$ ./kstacksampler.sh -p 9124 -n 100 -i .05 | grep -v 0xffffffffffffffff | sed 's/State:\t//g'| sed 's/\[<.*>] //g' >stack_sample_example1.txt
Step2: flame graph
$ cat stack_sample_example1.txt | ../FlameGraph/stackcollapse-stap.pl | ../FlameGraph/flamegraph.pl --title "Kernel stack profiling - Example 1, network-related bottleneck"> kstacksampler_Example1_network_bottleneck_Fig1.svg
The resulting flame graph is:

Figure 1: Flame graph of a process that is network-bound and spending the bulk of its time on TCP stack waiting for messages to arrive, as detailed in Example 1 in the text. Click here for a svg version of the graph.
{kind=link}
From the flame graph of Figure 1 you can see that the process is sleeping for a large fraction of its time and that the large majority of the traced operations are related to network/TCP communication. This confirms what found earlier with pidstat and Oracle instrumentation. Kernel stack sampling has helped to find/confirm the root cause of the performance issue.
Additional investigations:
Without going into too many details, which is not the scope of this example, you can find interesting to take one additional step and use the results of the analysis to apply and measure some changes to make the process go faster. The general idea is to use larger "data transfers" and reduce the number of round trips, therefore limiting the impact of the network latency. A simple change in the context of this Oracle-based example is to increase the number of rows fetched at each step by changing the arraysize parameter in SQL*plus and set it to the maximum allowed value: "SET ARRAYSIZE 5000" (arraysize was set to 100 in the previous case and in the tracing data of Figure 1). Other and similar options are also available at the TCP/kernel level, for those interested in further tuning. The outcome of the change of arraysize is a measurable reduction of the percentage of the elapsed time that is time spent waiting on TCP operations. More importantly this drives the throughput up (from 6 MB/s in the case of Figure 1 to about 20 MB/sec). Also pidstat shows that the CPU utilization increases (from 6% to about 28%). Similar observations can be done using Oracle instrumentation with V$ views. Finally the flame graph for the tuned process can be seen in Figure 1b. Notably the percentage of time spent with process status=running has considerably increased (more useful work is being done per unit of time).

Figure 1b: Flame graph of the process described in Example 1 after changing the parameter arraysize from 100 to 5000. An increase in CPU usage can be seen in this flame graph compared to what is represented in Figure 1 (taken with arraysize=100). This change correlates with higher network throughput and faster query execution. Click here for a svg version of the graph.
{kind=link}
Additional test case details:
I have created the case of Example 1 using Oracle running in a VM and connecting to it via a sshd tunnel. The tunnel was set up using putty: putty -P <forwarded_port> -L 1111:DB_host:1521 oracle@VM_host). 1111 is the locally forwarded port, 1521 is the Oracle listener port on DB_host, <forwarded port> is a port on the VM_host forwarded into port 22 (sshd) of the DB_host. SQL*plus on a client machine was used to connect to the DB and run the query: "SELECT * FROM LARGETABLE;", where LARGETABLE is any table big enough so that the query runs in a few minutes. Another tip is to "set autotrace traceonly" before running the query to suppress the output to the screen.
Example 2: Investigation of an Oracle process doing random I/O.
This example is about investigating I/O-bound processes. In particular Figure 2 shows the output of kernel stack profiling and flame graph for an Oracle process executing Kevin Closson's SLOB workload. The same two steps as detailed above in Example 1 have been used to collect data and produce the flame graph. The workload is mainly random read from block devices. The DB server used for this example runs in a VM and Oracle is configured to use ASM. The stack traces show that the process time is mostly spent either doing I/O or waiting for I/O calls to complete. Two different type of I/O system calls are visible in Figure 2: calls for blocking I/O (pread64) and calls for asynchronous I/O (io_submit and io_getevents). At the Oracle level this is reported using the wait events "db file sequential read" (blocking I/O) and "db file parallel read" (asynchronous I/O). You can read more on the topic of tracing Oracle I/O at "Life of an Oracle I/O: Tracing Logical and Physical I/O with SystemTap"
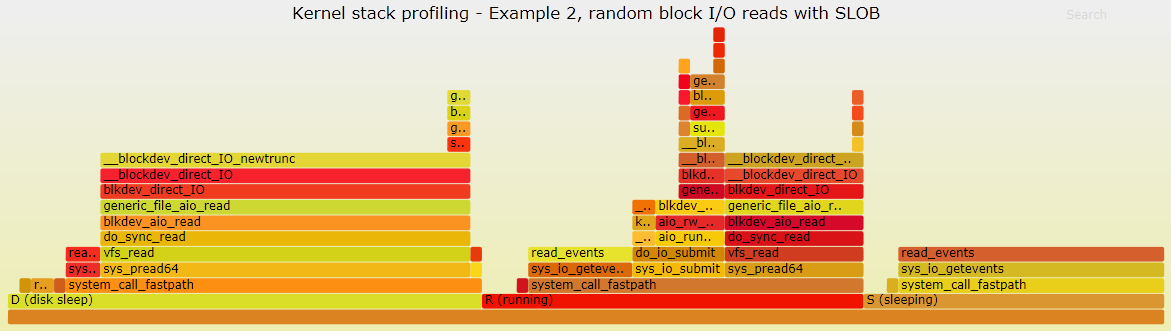
Figure 2: Flame graph visualization of the stack profile for an I/O bound Oracle process running SLOB. The process is spending the majority of the time executing I/O or waiting for I/O calls to return. Click here for a svg version of the graph.
{kind=link}
Conclusions
Stack profiling and flame graphs are useful techniques and tools for troubleshooting performance investigations at the OS-level. Flame graphs are often used for profiling CPU-bound processes, for example in Linux with the help of perf. This post describes how stack profiling of kernel traces from the /proc filesystem can be used to investigate workloads that spend a significant amount of their time off-CPU and/or in kernel code (for example sleeping for I/O or network system calls to complete). A simple tool for stack sampling, kstacksampler.sh, complements this blog post together with two examples of its use for investigating network and I/O-bound Oracle processes.
References and acknowledgements
Brendan Gregg's flame graphs are the starting ground for this work. Tanel Poder has also published several original investigations of stack profiling for Oracle troubleshooting, notably this included the blog post "Peeking into Linux kernel-land using /proc filesystem for quick’n’dirty troubleshooting". Kevin Closson has also published work on stack profiling with perf and OProfile and he is the author of SLOB, used in Example 2 of this post.