This is a short post introducing a notebook that you can use to play with a simple analysis of High Energy Physics (HEP) data using CERN open data and Apache Spark. The idea for this work started with a concept for a technology demonstrator of some recent developments on using Spark for data analysis in the context of HEP. The actual analysis used in the final version comes from previous work published by the LHCb open data project, suitable for a relatively large audience, where I have filled in some guesses answers to the exercises using Spark SQL. As it has been a fun exercise for me to go through it, I thought it could be of more general interest. This is also a sort of experiment for what concerns the audience too, as the notebook attempts to interest a heterogeneous group, including data scientists, physicists, citizen scientists and students (let me know how this works for you). Here are the links to the notebook:
Jupyter notebook on GitHub at: LHCb_OpenData_Spark.ipynb
CERN SWAN service users: use this link to the notebook on CERN Box
There are a few key elements that have appeared or matured in the last few years and that have made this exercise possible (see also the credits section):
- The CERN open data portal - a portal where LHC experiments share and make available for download part of their data (several 100s of TBs are available as I write this, see also this link).
- Recent developments of Apache Spark, in particular the DataFrame API (Spark SQL), in addition to PySpark on Jupyter notebooks.
- Spark-ROOT, a Spark data source able to read files in ROOT format. ROOT is the most used framework for HEP data processing and most of CERN open data files are in ROOT format.
- A notebook developed by the LHCb collaboration and shared on a open source license as part of their open data project, with an analysis at the level of advanced high school students and particle physics enthusiasts.
What you can learn: The main idea for the notebook is to be a technology demonstrator and a learning resource, possibly motivating you to explore these topics in more depth. Here are some of the key points:
- Experimenting with using the CERN open data portal for accessing data from LHC experiments.
- Learning how to read physics data stored in ROOT format into Spark Dataframes.
- See an example of how Spark SQL, PySpark, Pandas and Jupyter notebooks can be used for (physics) data analysis and for sharing exercises and results.
- Have fun with trying some of the exercises yourself!
An example figure from the notebook, just to give you an idea of what the exercises proposed there are like:
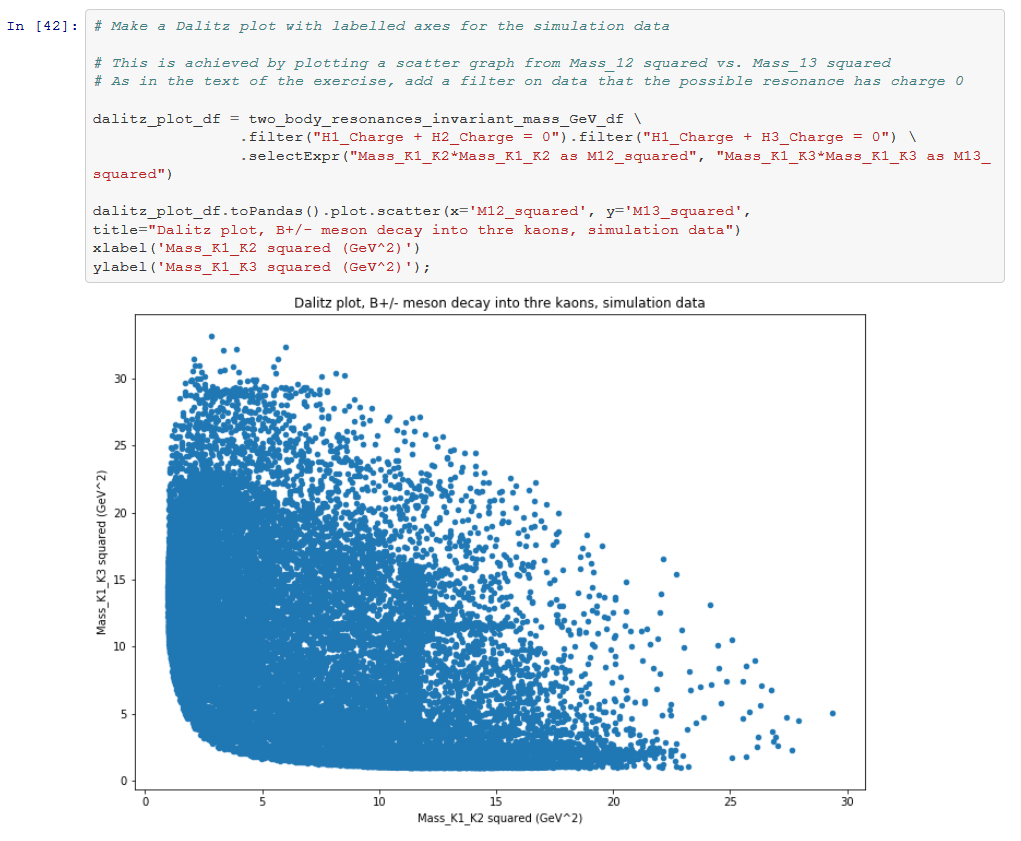
Credits:
The Spark-ROOT connector has been developed by the CMS Big Data Project and DIANA-HEP. The exercises, text and images in the example notebook have been developed by the LHCb open data project. See also links at this page for additional examples and info. This note has been developed in the context of the CERN Hadoop and Spark service and the CERN openlab project on data analytics and has profited of the collaboration of several members of those teams.