Authored By: Aman Pratap Singh and Prasanth Kothuri
Published By: CERN IT Hadoop and Spark Service
Introduction
The Large Hadron Collider (LHC) is the largest and most powerful collider in the world. It boosts the particles in a loop 27 kilometres in circumference at an energy of 6.5 TeV (teraelectronvolts), generating collisions at an energy of 13 TeV. The resultant mammoth energy density created is used to break the strong and weak nuclear forces to study the standard model of elementary physics and the smallest building block of the universe. Are there other ways to accelerate particles to high energies over short distances?
Background
Any traditional particle accelerator uses Radio Frequency (RF) cavities to accelerate particles to larger speeds. This is accomplished by alternating the electrical polarity of positively and negatively charged zones within the RF cavity, with the combination of attraction and repulsion accelerating the particles within the cavity. In layman term, Electric field switches from positive to negative at a given frequency, creating radio waves that accelerate particles in bunches and electromagnets are used to steer the particles in the collider.
However, the future of particle accelerators could be smaller particle accelerators achieving similar energies. Advanced Wakefield Experiment (AWAKE) is one such proof of concept experiment at CERN which hopes to achieve this. AWAKE aims to accelerate a low energy electron bunch from 15–20 MeV to several GeV over a short distance (10m). The technical coordinator and project lead Dr Edda Gschwendtner introduces the AWAKE experiment in this video.
In the plasma wakefield experiment, we use plasma instead of cavities. When we inject high energy proton beam into a 10m long plasma cell, strong wakefields are created similar to waves being created after a boat passes by. Hence, When we inject electron beam at lower energies they can bank on these wakefields to get accelerated similar to how nearby surfers to passing boat can bank on waves generated after a boat passes by and get accelerated.
In 2017, AWAKE proved the existence of wakefield after a proton beam was passed through a plasma cell. On 26th May 2018, AWAKE accelerated electrons by passing an electron beam into these wakefields which were previously generated by the proton beam. The electrons were accelerated by a factor of around 100 over a length of 10 metres: injected at an energy of around 19 MeV, they reached an energy of almost 2 GeV. This acceleration gradient achieved is 40 times better than the results achieved at LHC. In this interview, Edda talks about the experiment, results as well as the future of AWAKE.
AWAKE explores the use of plasma to accelerate particles to high energies over short distances. Currently, AWAKE is a proof of concept experiment at CERN. In its experimental year 2017–18, AWAKE discovered a lot of data which needs to be analyzed.
This led to the foundation of the idea for building a library pyAwake.
Google Summer of Code and High Energy Physics (CERN-HSF)
It’s an initiative by Google to link interesting open-sourced problem statement to capable students. It’s one of the most prestigious competitions to be part of and every project receives funding and global recognition.
Particle physics is an exciting field where large collaborations of scientists collect and analyze petabytes data from high-energy physics experiments, such as the Large Hadron Collider, hosted at the CERN laboratory in Geneva, Switzerland. CERN has participated in the GSoC since 2011 and since 2017 the program has expanded to involve the high-energy physics community under the umbrella of the HEP Software Foundation.
On March 25, 2019, the complex problem statement of AWAKE was released as part of the program by mentors Dr Spencer Gessner and Dr Marlene Turner through CERN High Energy Physics Software Foundation. CERN-HSF has 38 projects with 30 organizations. The objectives of the problem statement were as follows :
- To read about 12TB of data created during 2017–18 experimental run and create a faster and simpler AWAKE database.
- To supply API for searching and visualizing multiple datasets in the timestamp range.
- Using NumPy, SciPy, and Matplotlib for data analysis and visualization.
- Porting existing analysis done by AWAKE Analysis tools.
- Encapsulate in library structure and provide example notebooks.
From March 25, 2019 to April 9th, 2019, I was constantly in touch with my mentors at CERN to build a proposal worthy of submission in the program. The proposal had to take in account how to build a database engine and then build generic analysis subroutines on top of that database engine so that it’s convenient for any novice in computer science to analyze on data recorded. On April 2nd, I submitted my proposal on “Building a python based library for AWAKE analysis” (proposal link). Out of 7,555 proposals submitted in GSoC 2019 across 103 countries, 45 proposals were submitted on the problem statement of AWAKE out of which my proposal was finally accepted. In total, CERN-HSF is hosting about 33 interns out of ~1100 interns selected all over the world.
Building a Database
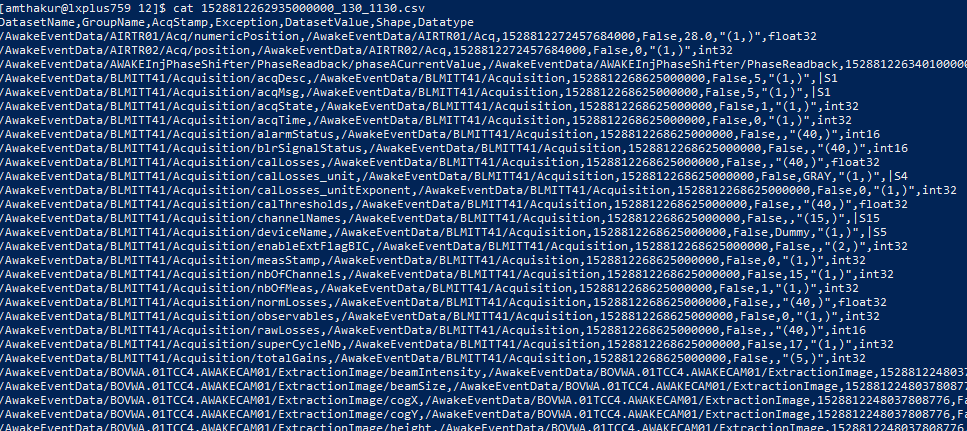
In the first attempt, we worked on writing multi-threaded sub-routines in Python to index the entire database. For each HDF file (Hierarchical Data Format), there will be one CSV file with one-to-one mapping whilst saving only relevant dataset metadata information. This allowed each file to compress from 50–60 MB to 250 KB. In total around 0.5 million files, CSVs were created reducing the 12 TB footprint to 150GB.
Unfortunately, it took about 3 hours to index about 25,000 files with 8 cores. So, we decided to go with Apache Spark technology provided by IT-DB-SAS and jupyter notebooks provide by CERN SWAN service. SWAN (Service for Web based ANalysis) is a platform to perform interactive data analysis in the cloud with the posssibility to offload computations to large Spark clusters, Spark is an open-sourced distributed general-purpose cluster-computing framework. SPARK can process data from AWAKE HDF data repository storaged on EOS (which is a disk-based, low-latency storage service), partition data across serveral cluster nodes, where it can be computed by running python sub-routine and then stored in Resilient distributed dataset (RDD) data format which allows SPARK to hide most of the computational complexity from the users.
With the help of Prasanth Kothuri and Piotr Mrowczynski, I was able to deploy my sub-routine on SPARK (Full code). In a nutshell, the sub-routine will travel in each HDF file using depth-first search technique and extract relevant metadata and attributes stored for each group/dataset and store it in a CSV. Since this was a data reduction task and not a data processing job, SPARK team was kind enough to provide optimal spark configuration (spark.executor.memory and spark.kubernetes.memoryOverheadFactor etc) for the execution of this task and troubleshooting tools like SparkMonitor jupyter plugin and grafana dashboard to live monitor the progress of the job and optimize.
With ~256 nodes, I was able to run the AWAKE data reduction of 12TB data in 3 hours as opposed to 30 days running on single python thread, which is clearly a feat for engineering teams working at CERN. In addition data analysis platform like SWAN allows data analysts and data sciences to focus on the analysis and leave the infrastructure to the capable hands of CERN IT.
If you have access to CERN’s infrastructure you can access the files by logging in to the server using ssh and try the following command and you should see the following in output.
cat /eos/experiment/awake/CSVFiles/2018/06/12/1528812262935000000_130_1130.csv
BUILDING A DATABASE ENGINE AND VISUALIZING TOOLS
After the database for 500,000 files was up and running, it was crucial to build a database engine which would allow scientists to query data and visualize with ease and in a generic manner. Since the users might be a novice in computer science, we decided to build a master search function to cater to every need. The flow of control has been explained in the below diagram and the source code for Searching engine is here.
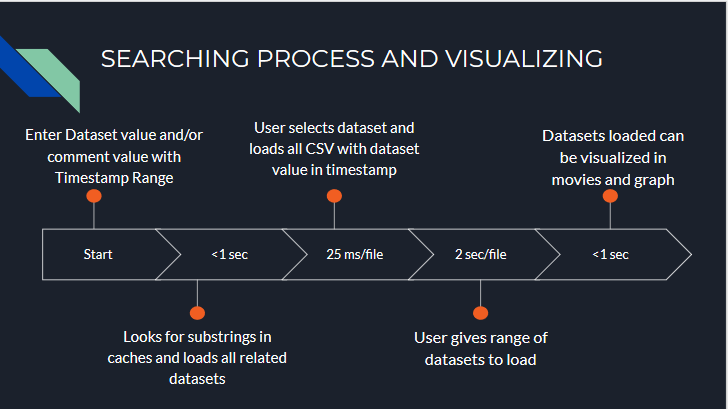
The master search function has the following input parameter: dataset keywords, comment keywords, starting timestamp, ending timestamp and dataset cuts. The user then gets to choose the correct dataset and the date range for loading multiple datasets in the form of dicts. This array of dicts can be passed to visualizing modules for visualization in the form of movie or collection of images in pyplot. This can be achieved with the following code snippet.
from pyawake.Searching import searching from pyawake.Visualizing import visualizing dataset_cuts = “/AwakeEventData/TT41.BCTF.412340/Acquisition/totalIntensityPreferred < 100.0,/AwakeEventData/TT41.BCTF.412340/Acquisition/totalIntensityPreferred > 1.0” dataset_image = searching.search(“bovwa 04 raw”, “”, “2018–05–12 00:00:00”, “2018–05–12 23:59:59”, dataset_cuts) visualizing.displayMovie(dataset_image)
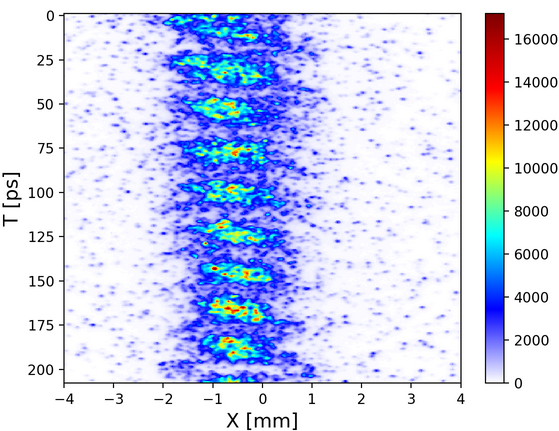
The displayMovie function uses analyses.frame_analysis python file from AWAKE_ANALYSIS_TOOLS package developed by my mentor Spencer. It applies a necessary filter like scipy.signal.medfilt and displays in a movie fashion. The below example is the result of visualizing streak dataset in May 2018 and this the link for movie.
Streak Camera is an instrument used for measuring the variation in the pulse of light’s intensity with time. In this particular image, there is a beam propagating with batches in high and low electron density alternatively. This information is used to derive whether the experiment is successful by determining whether injected electrons are accelerated to higher energies.
For doing specific analysis, we can use load_column() command instead of search() and it’ll return a 2D array with the values of all the columns. This is extremely useful for doing covariance analysis in the future. For visualizing multiple images at once we can use method visualize_multiple_image(). The source code for visualizing modules can be found here and for AWAKE_ANALYSIS_TOOLS can be found here.
Both these packages are effectively deployed and their example notebooks will be uploaded on SWAN. The testing module and example notebook are also added to my GitHub repository as part of GSoC submission
COVARIANCE ANALYSIS & FUTURE SCOPE
Since the package was completed and deployed, My mentor Spencer was kind enough to work with me in doing a covariance analysis on Streak dataset with the help of application of the package pyAwake.
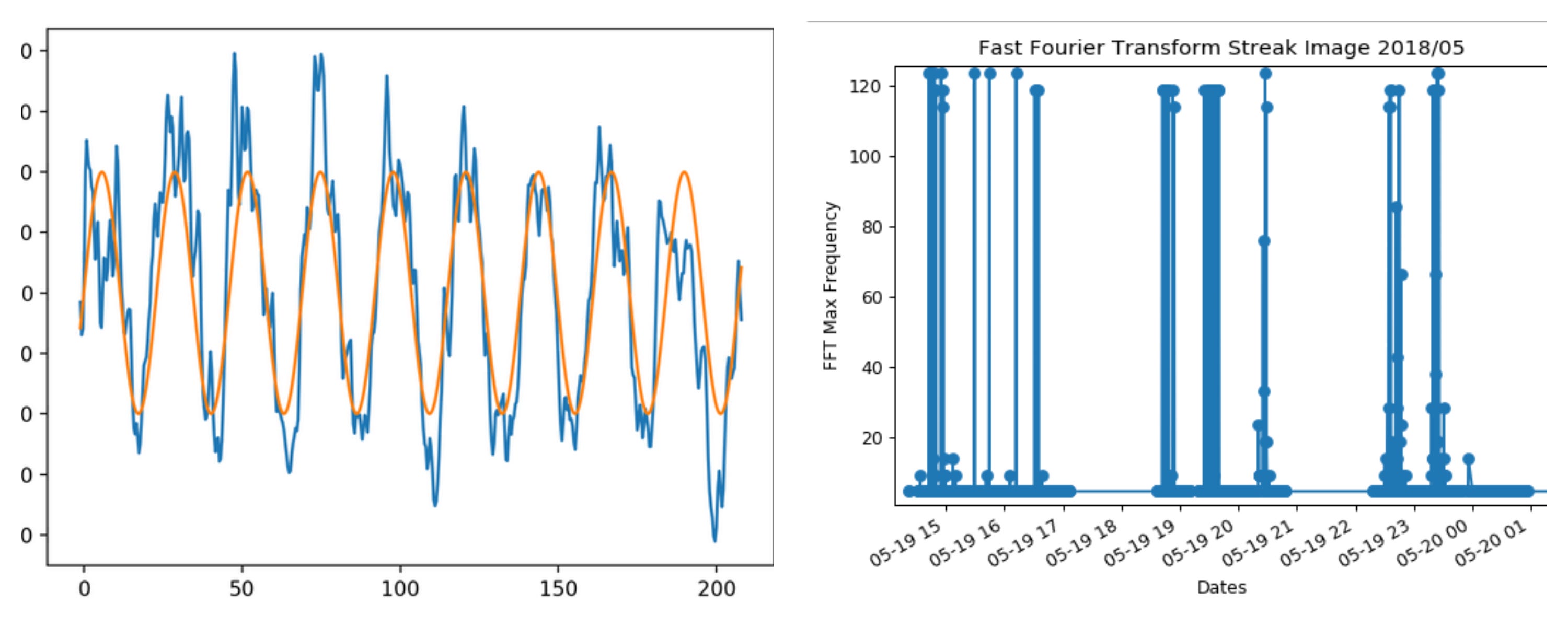
All images discovered by AWAKE are nothing but a collection of analog signals. So we can perform a Fast Fourier Transform (FFT) on each image to determine the frequency of each signal. The first image shows how FFT tries to match the frequency of the signal and Second shows FFT for 1 month (17,000 files) of data discovered in May 2018. This kind of analysis is very easy to execute after the introduction of pyAwake (code) as we can now compare multiple datasets across thousands of other similar datasets.
The peaks in the above image indicate that these datasets were discovered in similar conditions. We can now scrutinize more by drawing covariance analysis for each dataset. Each dataset is comprised of 512*672 values. Hence, if we apply FFT for each column (i.e 672 columns), we will get the frequency of the signal for each column of the dataset. If we compare each column with other columns and notice similar values, we can conclude that the frequency is bleeding to other columns which can further help in proving that the electrons are getting accelerated
EXPERIENCE, ACKNOWLEDGMENTS AND IMPORTANT LINKS
Google Summer of Code is much more than handsome stipend and fame. It’s a excellent opportunity to connect with some of the most talented people in this world working on great projects. I’d like to formally thank Google for coming up with GSoC program. I would also like to thank CERN SWAN service, CERN IT Hadoop and Spark Service, especially Mr. Prasanth Kothuri who worked with me in parallelizing the data reduction with Spark, providing Spark Kubernetes cluster to run the reduction stage at scale, publishing the software and analysis notebooks in the gallery for wider AWAKE audience and generally mentoring me in new technologies such as SWAN (Jupyter notebooks) and SPARK.
I would like to thank my mentors Dr Marlene Turner who constantly helped me understand the physics in our weekly journal class and Dr Spencer Gessner who selected me, mentored me and introduced me to the AWAKE team at CERN. It has been an amazing journey !
AWAKE Data Reduction with Spark and Jupyter Notebook