Introduction
International organisations can have multiple official languages, in these cases usually their workflows/processes are designed to support that. CERN is one of those organisations, it's official languages are French and English. Therefore one of our tasks was to make the Open Days reservation system bilingual. In this article you will read about the choices we made to internationalize the system, what obstacles we faced and what solution we went for.
This post is part of the "Open Days reservation system - 2019" series. If you want to know more about the CERN Open Days project, you can find it in the following post.
Translation layers for Open Days reservation system
From the development perspective it is important to have a rough idea about the deliverable system before you start working on it. Of course it is not possible to plan everything in advance, but it is important to have a basic understanding of the requirements, which the system needs to meet. Internationalization (i18n) is one of these aspects, and its importance increases as the system goes from internal use to external use.
I18n depends highly on the technologies and on the architectural design, which you select for your project. Certain things can also fall out while you are checking the project as a whole. For example at which phase will be the final display text available, the technical skill level of the translators, how the components are going to share the translation, etc. It is important that you know the answers for these in advance so you can lower the risks and the amount of dirty solutions/hacks as you get closer to delivery.
We knew from the beginning that the production data (entrances + opening times + capacity, etc.) for the Open Days would only be available when the registration period started. We were also aware that during booking we want to have basic reporting which shows the progress of the reservations (how many tickets are still available, how people are going to arrive to where , etc. ). According to this additional information and due to the layer-separated system, consisting of front-end, back-end and database layers, we found the layer-divided translation approach the best fit.
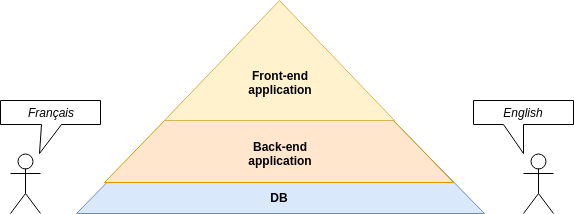
The image demonstrates a layer separated translation design. Imagine your application/system as a pyramid which represents the stable/final version of the work. This is what the different language speaking users are going to interact with. The workflows should not/are not going to change based on the language, they are stable as a constructed building. On the pyramid you can see our different i18n layers, which are the following:
- In our database we formed a tiny translation layer, we added the most frequently used and the most dynamically changing content such as list elements (radio button, checkbox, combobox, etc.). Since they were living there, it increased the number of executed queries as the content was loading in the end-users browser. One common practice for lowering the number of executed queries is to cache the end results of the queries and reuse them. By putting the selection options into the database we added an extra flexibility to our development process. This became measurable as we were building the drill down functionalities for the dashboard on the top of the gathered data. Keeping only one single source of truth helped us to avoid hardcoding the selection lists for data gathering and reporting.
- On our back-end application layer we had a REST API based application implemented in JAVA using Spring boot. This layer had more translations than the database layer. Here the translations were about the different errors which could occur while loading information from the database or validating and storing information to the database. Since for our solution we did not use user profiles and because of our stateless system design every message coming from the front-end included the preferred language.
- The biggest portion of the translation lived inside the front-end layer. For this we selected Angular, because it allows collaboration in a standard way not just between the developers, but between the translator team and the developer team also.
The maintenance of the different display languages became very simple once we got the right i18n design. For the back-end application and database layers the design was straight forward, but for the front-end we did not get it right in the first iteration. Once we got that layer’s i18n design right, we were able the benefit from simplified and collaborative usage. In the second part of this post we will focus on what obstacles we faced for the front-end layer and how we solved them.
Our experiences with i18n for Angular
Angular’s simplicity and true power lies in its command line interface (cli). It has an out-of-the-box approach for internationalization. You add translation decoration on html tags and with the help of the cli you extract them into resource files. For the resource files we used the XML-based XLIFF format. Let’s see the concept through an example.
Here is our decorated html tag:
<div>
<span i18n="welcome page| general greetings @@greetings">Hello</span>
</div>
Here is the relevant resource file part which will be generated :
...
<trans-unit id="greetings" datatype="html" approved="yes">
<source>Hello</source>
<target state="translated">Bonjour</target>
<context-group purpose="location">
<context context-type="sourcefile">app/Pages/welcome-page/welcome-page.component.html</context>
<context context-type="linenumber">4</context>
</context-group>
<note priority="1" from="description">general greetings </note>
<note priority="1" from="meaning">welcome page</note>
</trans-unit>
...
From the example you can see that the cli generates a “trans-unit” block for each i18n decorated tag. The "source" tag contains the text to be translated in the source language, and is taken from the span above. The "target" tag contains the translation. The “context-group” tag lists all the different occurrences of the string. This is needed as the translation block can be used for multiple html tags if the identifier and the decorations are the same. In the translation decoration we can add extra information for the translator, like “meaning” and “description” in the example. These are for providing extra context for the translators. You can find more detailed information about Angular i18n here.
Note that if you are going with named (@@greetings) translation units then you have to pay attention on the right naming convention. You should avoid to add the page name or component name to the translation unit id, because the cli is designed to handle multiple occurrences and you don’t want to manage 2 or more translation units with the same content. For these cases it’s better to use the exact same decoration in both places. Also it is very important to understand that for every new i18n decoration, source text or translation context change it is required to regenerate the resource files.
Once you have the resource files with the translations you need to build individual applications for each translated language. This means that translation is done during build time and not during runtime. This results in translated content reaching the user’s browser faster.
At the beginning of our project updates to the translations didn't happen too often, so manually managing the XLIFF-files was not a problem. As new decorations were added we extracted the XLIFF-files and manually "merged" them with the old ones. When we entered the pre-release phase of development this process became insufficient. By that time the translation files grew big (1 decorated line generates 10 lines) and merging the already translated content manually became very time-consuming.
We needed a tool to help us improve our translation cycle, because it was not maintainable. As a result of our search we found xliffmerge. This tool merges new translation updates into existing XLIFF-files. With the help of this the developers no longer had to babysit the translation files, and could instead offload the work of translation to others completely, relying 100% on the tool to manage the files.
At first when as we started using the tool we faced some some difficulties, but thanks to the fast reply from the maintainer of the tool, Martin Roob, we managed to find the proper way to use it. The tool requires a source language to be defined, then from that source language it will generate a master resource file. The content of that master resource file will be merged to the other translation resource files. We manually started to edit this generated master file to apply the text changes for the English version. This caused us issues, because it was not properly displaying the modified text. Thanks to the quick reply from the maintainer we understood that the intented approach to change wordings for the source language is to directly edit the HTML source code, not to edit the generated master resource file. The maintainer suggested an alternative approach for us, which fits our use-case well. The suggested approach was to trick the tool into thinking the source language was some unrelated language, and instead have every real target language be a translation of this fake language. With this approach the appearance of our English web pages could be changed using the same method as the that for the French ones. A funny consequence of this is that the source language of the application technically became Norwegian, although in practice this language was treated as "English without our changes".
Xliffmerge helps with updates of the XLIFF-files, but you still need to edit them directly to perform translations. Virtaal is a tool we used that gives you a simple UI to edit the XLIFFs. It provides an opportunity for non-technicals to contribute and collaborate, without digging into XML files directly.