TOPIC
This post reports performance tests for a few popular data formats and storage engines available in the Hadoop ecosystem: Apache Avro, Apache Parquet, Apache HBase and Apache Kudu. This exercise evaluates space efficiency, ingestion performance, analytic scans and random data lookup for a workload of interest at CERN Hadoop service.
INTRO
The initial idea for making a comparison of Hadoop file formats and storage engines was driven by a revision of one of the first systems that adopted Hadoop at large scale at CERN – the ATLAS EventIndex.
This project was started in 2012, at a time when processing CSV with MapReduce was a common way of dealing with big data. At the same time platforms like Spark, Impala, or file formats like Avro and Parquet were not as mature and popular like nowadays or were even not started. Therefore in retrospect the chosen design based on using HDFS MapFiles has a notion of being ‘old’ and less popular.
The ultimate goal of our tests with ATLAS EventIndex data was to understand which approach for storing the data would be optimal to apply and what are expected benefits of such application with the respect to main use case of the system. The main aspects we wanted to compare were data volume and performance of
- data ingestion,
- random data lookup
- full data scanning
ABOUT THE EVENTINDEX DATA
ATLAS is one of seven particle detector experiments constructed for the Large Hadron Collider, a particle accelerator at CERN.
ATLAS EventIndex is a metadata catalogue of all collisions (called ‘events’) that happened in the ATLAS experiment and later were accepted to be permanently stored within CERN storage infrastructure (typically it is about 1000 events per second). Physicists use this system to identify and locate events of interest, group events populations by commonalities and check a production cycle consistency. In practice in means that both: frequent random data lookups (by a collision id) and (less frequent) sequential scans of certain collision attributes are performed.
Each indexed collision is stored in the ATLAS EventIndex as a separate record that in average is 1.5KB long and has 56 attributes, where 6 of them uniquely identifies a collision. Most of the attributes are text type, only a few of them are numeric. At the given moment there are 6e10 of records stored in HDFS that occupies tens of Terabytes (not including data replication).
TESTED STORAGE APPROCHES ON HADOOP
The same data sets have been stored on the same Hadoop cluster using different storage techniques and compression algorithms (Snappy, GZip or BZip2):
- Apache Avro is a data serialization standard for compact binary format widely used for storing persistent data on HDFS as well as for communication protocols. One of the advantages of using Avro is lightweight and fast data serialisation and deserialization, which can deliver very good ingestion performance. Additionally, even though it does not have any internal index (like in the case of MapFiles), HDFS directory-based partitioning technique can be applied to quickly navigate to the collections of interest when fast random data access is needed.
In the test, a tuple of the first 3 columns of a primary key was used as a partitioning key. This allowed obtaining good balance between the number of partitions (few thousands) and an average partitions size (hundreds of megabytes)
- Apache Parquet is column oriented data serialization standard for efficient data analytics. Additional optimizations include encodings (RLE, Dictionary, Bit packing) and compression applied on series of values from the same columns give very good compaction ratios. When storing data on HDFS in Parquet format, the same partitioning strategy was used as in Avro case.
- Apache HBase - scalable and distributed NoSQL database on HDFS for storing key-value pairs. Keys are indexed which typically provides very quick access to the records.
When storing ATLAS EventIndex data columns. Additionally, differential (FAST_DIFF) encoding of a row key (DATA_BLOCK_ENCODING) was enabled in order to reduce a size of HBase blocks (without this each row would have the length of 8KB).
- Apache Kudu is new scalable and distributed table-based storage. Kudu provides indexing and columnar data organization to achieve a good compromise between ingestion speed and analytics performance. Like in HBase case, Kudu APIs allows modifying the data already stored in the system.
In the evaluation, all literal types were stored with a dictionary encoding and numeric types with bit shuffle encoding. Additionally, a combination of range and hash partitioning introduced by using the first column of the primary key (composed of the same columns like in the HBase case) as a partitioning key.
RESULTS OBTAINED
The data access and ingestion tests were on a cluster composed of 14 physical machines, each equipped with:
- 2 x 8 cores @2.60GHz
- 64GB of RAM
- 2 x 24 SAS drives
Hadoop cluster was installed from Cloudera Data Hub(CDH) distribution version 5.7.0, this includes:
- Hadoop core 2.6.0
- Impala 2.5.0
- Hive 1.1.0
- HBase 1.2.0 (configured JVM heap size for region servers = 30GB)
- (not from CDH) Kudu 1.0 (configured memory limit = 30GB)
Apache Impala (incubating) was used as a data ingestion and data access framework in all the conducted tests presented later in this report.
Important: Despite the effort made to obtain as much precise results as possible, they should not be treated as universal and fundamental benchmark of the tested technologies. There are too many variables that could influence the tests and make them more case specific, like:
- chosen test cases
- data model used
- hardware specification and configuration
- software stack used for data processing and its configuration/tuning
SPACE UTILIZATION PER FORMAT
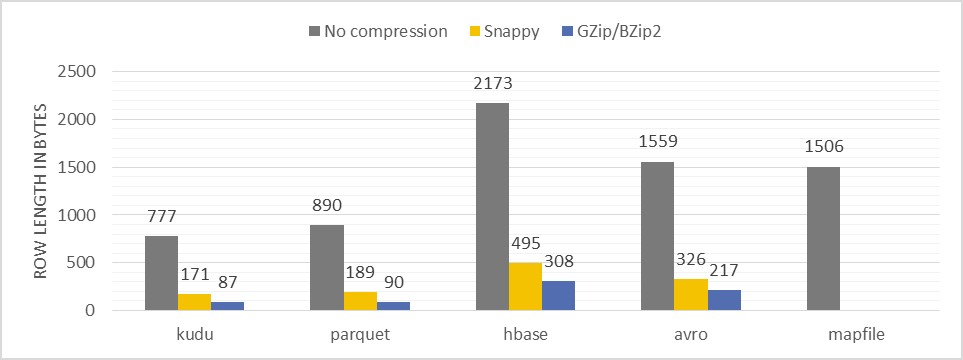
The figure reports on the average row length in bytes for each tested format and compression type
Description of the test: Measuring the average record size after storing the same data sets (millions of records) using different techniques and compressions.
Comments:
- According to the measured results, data encoded with Kudu and Parquet delivered the best compaction ratios. Using compression algorithms like Snappy or GZip can further reduce the volume significantly – by factor 10 comparing to the original data set encoding with MapFiles.
- HBase due to the way it stores the data is a less space efficient solution. Though compression of HBase blocks gives quite good ratios, however, it is still far away from those obtain with Kudu and Parquet.
- Apache Avro delivers similar results in terms of space occupancy like other HDFS row store – MapFiles.
INGESTION RATE PER FORMAT
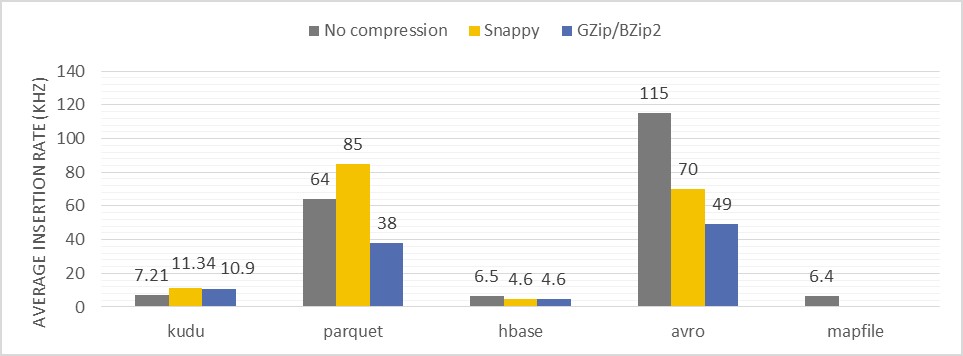
Figure reports on the average ingestion speed (103 records/s) per data partition for each tested format and compression type
Description of the test: Measuring of records ingestion speed into a single data partition.
Comments:
- Because Apache Impala performs data reshuffling in order write into a single HDFS directory (Hive partition) in serial, the results obtained for HDFS formats and HBase or Kudu can be directly compared on a field of single data partition ingestion efficiency. Writing to HDFS files encoded with Avro or Parquet delivered much better results (at least by factor 5) than storage engines like HBase and Kudu.
- Writing to HDFS files encoded with Avro or Parquet delivered much better results (at least by factor 5) than storage engines like HBase and Kudu. Since Avro has the most lightweight encoder it achieved the best ingestion performance
- On the other end of the spectrum, HBase in this test was very slow (worse than Kudu). This most likely was caused by a length of a row key (6 concatenated columns), that in average was around 60 bytes. HBase has to encode a key for each of the columns in a row separately, which for long records (with many columns) can be suboptimal.
RANDOM DATA LOOKUP LATENCY PER FORMAT
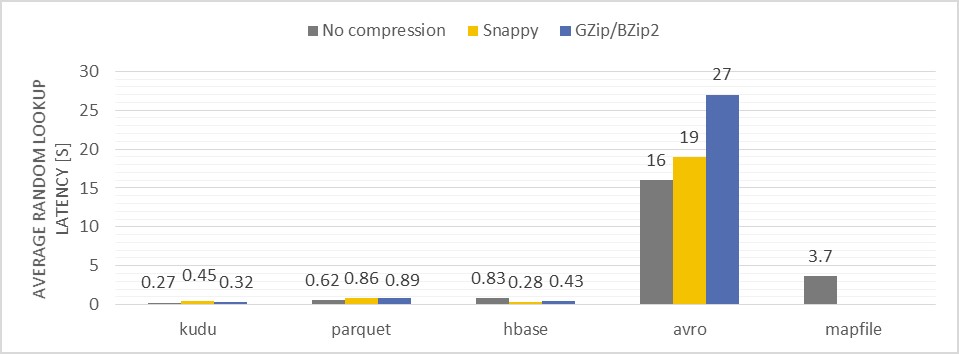
Figure reports on the average random record lookup latency [in seconds] for each tested format and compression type
Description of the test: Retrieving a non-key attribute from a record by providing a record identifier (a compound key)
Comments:
- When accessing data by a record key, Kudu and HBase were the fastest ones, because of usage of a built-in indexing. Values on the plot were measured with cold caches.
- Using Apache Impala for random lookup test is suboptimal for Kudu and HBase as a significant amount of time is spent to set up a query (a planning, a code generation etc) before it really gets executed – typically it is about 200ms. Therefore for low latency data access it is advised to skip Impala and use dedicated APIs (we tried also this approach and results for Kudu and HBase were similar – with cold cache <200ms with warmed up cache <80ms).
- In opposite to Kudu and HBase, retrieving data from an individual record stored in Avro format can only be done in a brute force scan of entire data partition (reminder – data are partitioned by part of a record key, so partition pruning was applied in such case). Average partition is sized in GB, thus getting the desired record takes seconds (depends on IO throughput) and uses a significant amount of cluster resources. This ultimately reduces the number of concurrent queries that has to be executed at a full speed on a cluster.
- The same problem applies to Parquet, however, columnar nature of the format allows performing partition scans relatively fast. Thanks to column projection and column predicate push down, a scan input set is ultimately reduced from GBs to just a few MBs (effectively only 3 columns were scanned out of 56)
DATA SCAN RATE PER FORMAT
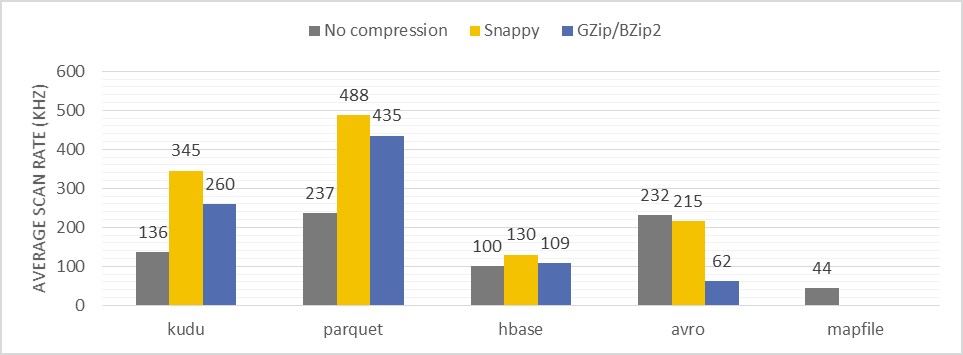
Figure reports on the average scans speed with the same predicate per core [in k records/s] for each tested format and compression type
Description of the test: Counting the number of records having certain substring in one of the non-key columns in entire record collection
Comments:
- Due to input set reduction by applying column projection, Parquet in this test had left behind Avro. It was not only the most efficient in terms of per-core processing rates but also the fastest to finish the processing.
- Unit of data access parallelization in case of Parquet and Avro is a HDFS file block – thanks to that it is very easy to evenly distribute processing across all the resources available on a Hadoop cluster.
- In terms of scanning efficiency Kudu (with Snappy compression) was not far from Parquet. It profited from column projection
- Scanning data stored in Kudu and HBase might be imbalanced since a unit of parallelization is a table partition is in both cases. Therefore the amount of resource involved in a scan depends on the number of given table partitions and as well as on their distribution across a cluster.
- In this test case, it was not possible to use Kudu’s native predicate push down feature, as Kudu did not support the used predicate. Additional tests proved that Kudu scans could be faster than Parquet when supported predicates are in used.
- Before performing the test with HBase the scanned column was separated in a dedicated HBase column family – this improved scanning efficiency by factor 5. That was still far away from Parquet or Kudu
LESSONS LEARNED FROM THE TESTS
In this paragraph we would like to share additional considerations on the use of data formats, with their pros and cons, as they have emerged from the tests with our reference workload:
- Storage efficiency – with Parquet or Kudu and Snappy compression the total volume of the data can be reduced by a factor 10 comparing to uncompressed simple serialization format.
- Data ingestion speed – all tested file based solutions provide fast ingestion rate (between x2 and x10) than specialized storage engines or MapFiles (sorted sequence).
- Random data access time – using HBase or Kudu, typical random data lookup speed is below 500ms. With smart HDFS namespace partitioning Parquet could deliver random lookup on a level of a second but consumes more resources.
- Data analytics – with Parquet or Kudu it is possible to perform fast and scalable (typically more than 300k records per second per CPU core) data aggregation, filtering and reporting.
- Support of in-place data mutation – HBase and Kudu can modify records (schema and values) in-place where it is not possible with data stored directly in HDFS files
Notably, compression algorithms played a significant role not only in reducing the data volume but also in enhancing the performance of data ingestion and data access. On all those fields Snappy codec delivered the best results for all tested technologies, much better than a plain encoding without compression (except Avro case).
CONCLUSIONS
The evaluation of the major data formats and storage engines for the Hadoop ecosystem has shown the pros and cons of each of them for various metrics, like reduction of overall data volume, simplifying ingestion and increasing the performance of data access.
Apache Avro has proven to be a fast universal encoder for structured data. Due to very efficient serialization and deserialization, this format can guarantee very good performance whenever an access to all the attributes of a record is required at the same time – data transportation, staging areas etc.
On the other hand, Apache HBase delivers very good random data access performance and the biggest flexibility in the way how data representations can be stored (schema-less tables). The performance of batch processing of HBase data heavily depends on a chosen data model and typically cannot compete on this field with the other tested technologies. Therefore any analytics with HBase data should be performed rather rarely.
According to the tests, columnar stores like Apache Parquet and Apache Kudu delivered very good flexibility between fast data ingestion, fast random data lookup and scalable data analytics. In many cases this provides the added advantage of keeping systems simple as only one type of technology is needed for storing the data and serving different use cases (random data access and analytics).
There are differences, Kudu excels at fast random lookup while Parquet excels at fast data scans and ingestion.
Alternatively to a single storage technology implementation, a hybrid system could be considered composed of a raw storage for batch processing (like Parquet) and indexing layer (like HBase) for random access. This would allow to fully profit from the best of each technology. Notably, such approach comes at a price of data duplication, overall complexity of the system architecture and higher maintenance costs. So if system simplicity is one of the important factors, Apache Kudu appears to be a good compromise.
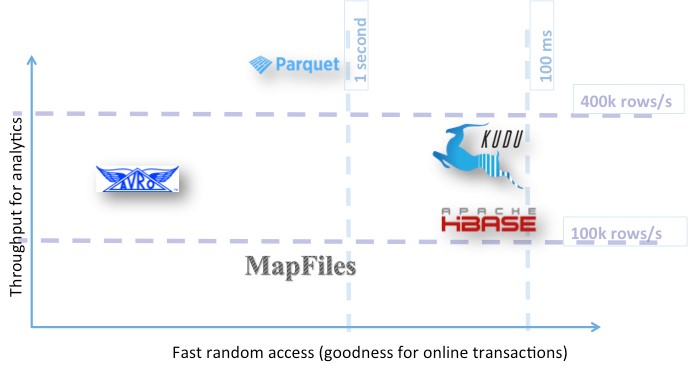
A schematic view of the results of the tests on Hadoop data formats and storage engines. Kudu and Parquet appears as a good compromise
between random data lookup and scalable data analytics.
ACKNOWLEDGEMENTS
This work has been made possible and funded by CERN IT, in particular in the context of the CERN IT Hadoop Service and Database Services. In particular the author would like to thank for relevant input during the tests and for discussions: Luca Canali, Rainer Toebbicke, Julius Hirvnac, Dario Barberis
REFERENCES
The work discribed in this blog post was presented during 22nd International Conference on Computing in High Energy and Nuclear Physics in Fall 2016.