Hi, my name is Priyanshu Khandelwal. I was amongst the 40 students selected from all over the world to work at CERN as an Openlab Summer Student 2019. I worked in the IT-DB-DAR section under the supervision of Mr Antonio Nappi.
Introduction
At CERN’s IT-DB-DAR section, there is ongoing work to migrate the hosting infrastructure from virtual machines to Kubernetes. Profiting of Kubernetes portability to evaluate how CERN’s services can run on public clouds - in particular, on Oracle cloud.
During the summer, I worked on automating the process of Infrastructural deployment on public/private clouds and making this deployment procedure cloud-agnostic.
As part of my project, we developed Terraform [1] (discussed below) modules that could deploy infrastructure (refer Figure 1) consisting of Kubernetes cluster, InfluxDb, Elasticsearch, Grafana and Kibana on Oracle Cloud. We also developed Terraform modules to create Kubernetes clusters and Magnum cluster templates on Openstack.
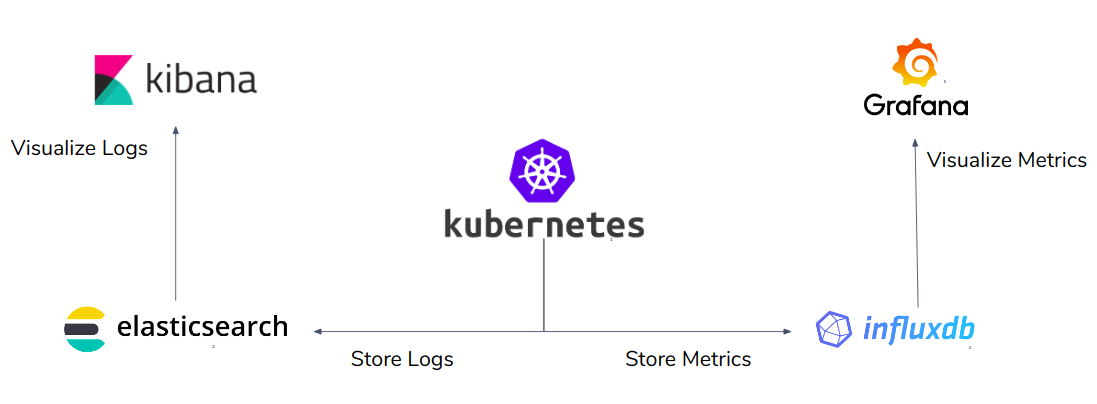
Figure 1. Infrastructure to be deployed on Oracle Cloud
About Terraform
Terraform [1] is an open source tool developed by Hashcorp which can create and manage cloud infrastructure. It uses Hashicorp Configuration Language (HCL) [2] for it’s configuration. With terraform, it is possible to specify the infrastructure components like network, subnet, compute instances etc in a set of declarative files in HCL. All major cloud providers have Terraform plugins available so Terraform can be used to deploy infrastructure on any of these cloud providers.
Creating a Terraform Module
Using Terraform, we specified the infrastructure that we wanted to deploy on the cloud as HCL code. We coded virtual machines and related infrastructure components like network subnet, virtual network etc as resources in Terraform.
An example is shown in Figure 2, where we declare a virtual machine resource of type “oci_core_instance” in terraform. The type represents the cloud provider, Oracle Cloud in this case. Further, several configuration arguments like Virtual Network Interface Card details, availability domain, shape, metadata etc can be added to the virtual machine resource.
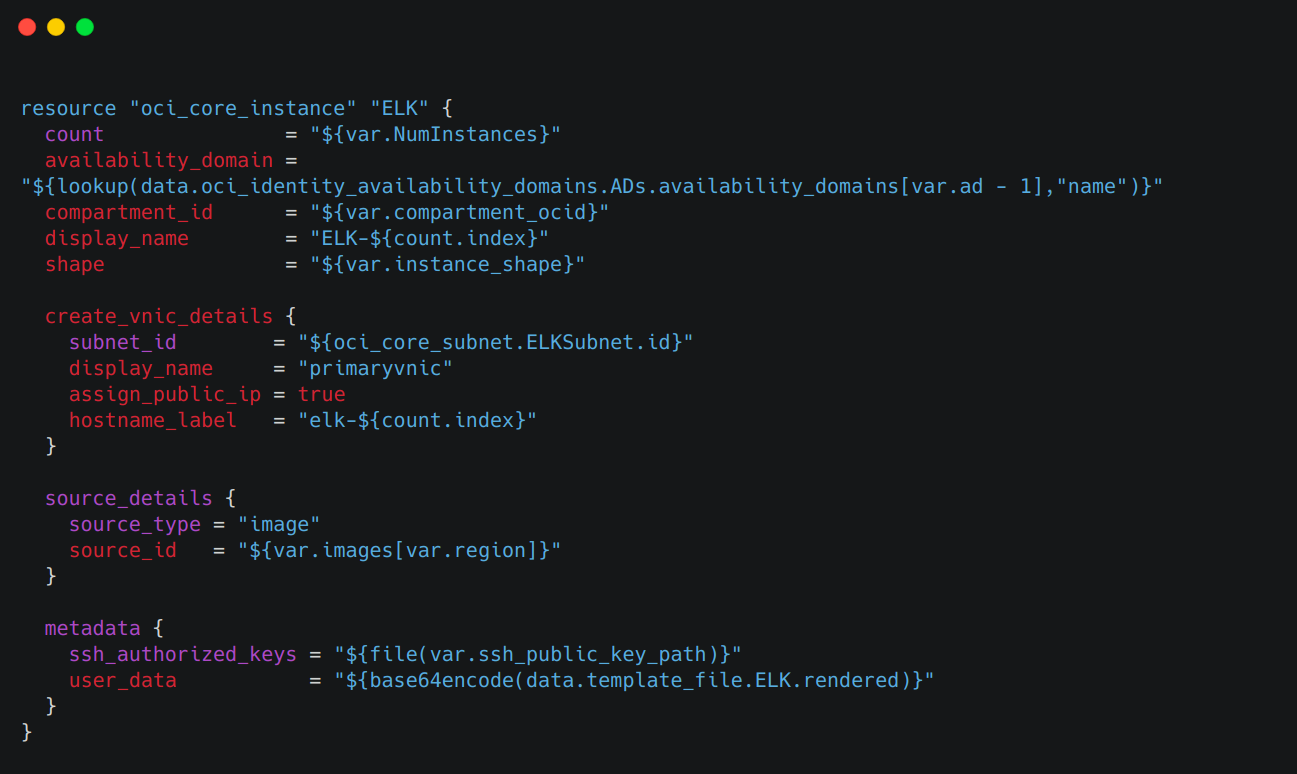
Figure 2. Coding a virtual machine as a resource in Terraform
After coding the infrastructure, we wrote bash scripts that could install particular software like Elasticsearch, Kibana, InfluxDb etc along with their dependencies on the virtual machine and configure the system for them. An example bash script is shown in Figure 3. These scripts were executed automatically on the virtual machine after it was provisioned.
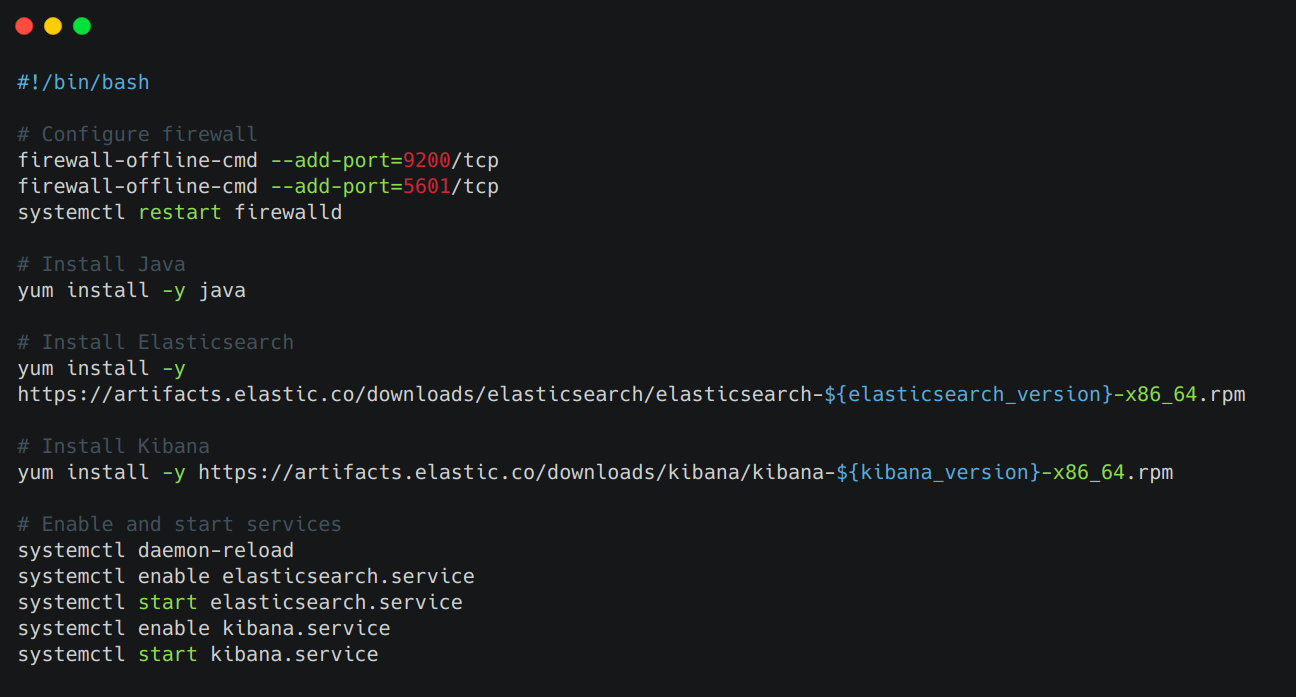
Figure 3. Bash script to setup Elasticsearch and Kibana on a VM
Then, we use “remote-exec” to copy the needed configuration files from the local system to the provisioned virtual machine (shown in Figure 4).
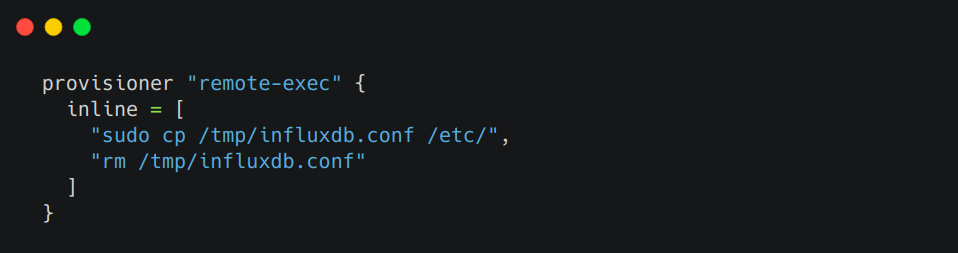
Figure 4. Using ‘remote-exec’ to copy files from local system.
Deploying a Terraform Module
The process to deploy any of the developed modules is the same for any public/private cloud. It consists of the following steps
- Enter the client secrets, passwords and preferences in the terraform.tfvars file. An example terraform.tfvars file is shown in Figure 5
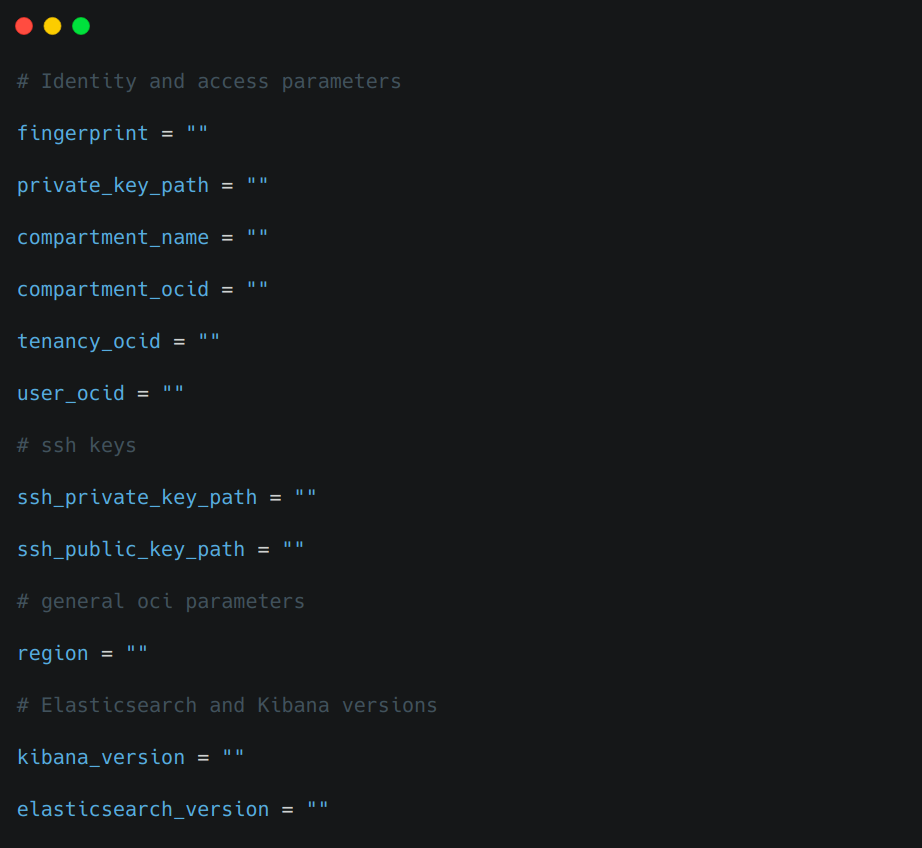
Figure 5. An example terraform.tfvars file
- Run the following command to download and install the cloud provider specific dependencies on your local system automatically.
$ terraform init
Run the following commands to deploy the current state of infrastructure to the cloud. Note that terraform would provide an analysis of all the infrastructure components that would be created or destroyed if the current state of the module is deployed before proceeding with the actual deployment.
$ terraform plan
$ terraform apply
Conclusion
This way, we were able to automate and simplify the entire process of infrastructural setup. The need to manually set up the system along with the dependencies is eliminated and developers no longer have to write long complex commands everytime they want to deploy infrastructure. The deployments are Cloud Agnostic as are able to use the same procedure of deployment for different cloud providers like Oracle Cloud and Openstack.
Challenges
Although we were able to achieve our goals, the following were few problems that we encountered in the development process -
- We started development with terraform version 0.11.x which was lacking some useful functionalities that were introduced in later releases. For instance, the API for terraform 0.12.x a function “fileexists()” to determine whether a file exists at a given path dynamically.
- Everytime we rename a terraform resource and run “terraform apply” to update it in the cloud, in spite of the infrastructure component getting updated with the new changes, it gets recreated on the cloud
Acknowledgement
Overall, I would say it was quite an enriching experience, the work was fun and the IT-DB-DAR team was amazing. I am greatly indebted to CERN for offering me such a wonderful opportunity and to my supervisor Mr. Antonio Nappi for guiding me throughout the program. This summer was one of the best summers I have ever had!
More details regarding the project are available here.