Topic: this post is about a simple implementation with examples of IPython custom magic functions for running SQL in Apache Spark using PySpark and Jupyter notebooks.
If you are already famialiar with Apache Spark and Jupyter notebooks may want to go directly to the links with the example notebook and code. If you want additional context and introduction to the topic, please read on.
- Notebook with examples of %sql magic functions for PySpark
- Code of the example IPython %sql magic functions
Jupyter notebooks and Spark SQL
Notebooks are very useful and popular environments for data analysis. Among others they provide a user friendly environment for exploratory analysis and simplify the task of sharing your work such as preparing presentations and tutorials. Jupyter notebooks in particular are very popular, especially with Python users and data scientist. One of the neat tricks that you can do with IPython and Jupyter notebooks is to define "custom magic functions", these are commands processed by IPython that can be used as shortcuts for needed actions and functions. The custom magic functions extend the list of built-in magic commands.
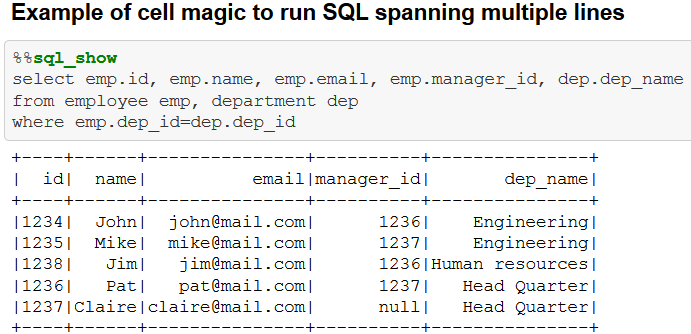
In particular when running SQL in notebook environments, %sql magic functions provide handy shortcuts to the code. Custom magic functions come in two flavors, one is the line functions, such as %sql, that take their input from one line. For those cases where you want to run SQL statements that span over multiple lines you can use %%sql which works with cell input.
Apache Spark is a popular engine for data processing at scale. Spark SQL in particular provides a scalable and fast engine and API for processing structured data (see also docs in the references section of this post).
In this post you will find a simple way to implement magic functions for running SQL in Spark using PySpark (the Python API for Spark) with IPython and Jupyter notebooks.
IPython magic
One typical way to process and execute SQL in PySpark from the pyspark shell is by using the following syntax: sqlContext.sql("<SQL statement>") (code tested for pyspark versions 1.6 and 2.0) . It is easy to define %sql magic commands for IPython that are effectively wrappers/aliases that take the SQL statement as argument and feed them to sqlContext (see the docs at "custom magic functions"). An example of magic functions for running SQL in pyspark can be found at this link to the code . The following magic functions are defined in the accompanying example code:
%sql <statement> - return a Spark DataFrame for lazy evaluation of the SQL
%sql_show <statement> - run the SQL statement and show max_show_lines (50) lines
%sql_display <statement> - run the SQL statement and display the results using an HTML table. This is implemented passing via Pandas and displays up to max_show_lines (50)
%sql_explain <statement> - display the execution plan of the SQL statement
An example of how the listed magic functions can be used to run SQL in PySpark can be found at this link to the example notebook. The code is simple and you can easily modify it to fit your needs ,if different from the provided examples.
Tips on how build a test environment
If you are not familiar with using Spark SQL and notebooks, here some links that can help you get started.
Download Spark from http://spark.apache.org/downloads.html
Note: you will not need to have Hadoop and/or a YARN cluster installed to run the tests described in this post.
An easy way to install a Python environment and Jupyter is by downloading Anaconda from https://www.continuum.io/downloads
If not yet installed in your test machine, you can download Java 8 from Oracle Technet: http://www.oracle.com/technetwork/java/javase/downloads/index.html
The Python shell for Spark can be started simply by running "pyspark".
If you want to run pyspark inside a Jupyter notebook, as in the example notebook provided with this post, you can do that by setting the environment variable PYSPARK_DRIVER_PYTHON prior to running pyspark. Example:
export PYSPARK_DRIVER_PYTHON=$PATH_TO_ANACONDA/bin/jupyter-notebook
I also find this additional (optional) configuration useful:
export PYSPARK_DRIVER_PYTHON_OPTS="--ip=`hostname` --browser='/dev/null' --port=8888"
Similarly if you just want to run pyspark under IPython using the command line (rather than the web notebook interface with Jupyter), you can set PYSPARK_DRIVER_PYTHON to point to the executable for IPython prior to running pyspark. Example:
export PYSPARK_DRIVER_PYTHON=$PATH_TO_ANACONDA/bin/ipython
The paragraphs just lists a few examples of how you can get started with running the code described in this post. There are other ways to start your Python notebook environment for Spark. Notably you can start the notebook with IPython/Jupyter first and later manually start the Spark Context and SQLContext, therefore bypassing the use of the pyspark tool/shell.
Links to documentation, references and previous work
Link to Apache Spark documentation on Spark SQL and DataFrames and PySpark API.
Spark SQL Language Manual, which is part of the Databricks User Guide.
Overview article on Spark: "Apache Spark: A Unified Engine for Big Data Processing" in Communications of the ACM November 2016.
Article with details on Spark SQL: "Spark SQL: Relational Data Processing in Spark", proceeding of SIGMOD 2015
I have covered in this blog other examples of how to implement and use %sql magic functions, see: "IPython/Jupyter Notebooks for Oracle" and "IPython Notebooks for Querying Apache Impala".
Previous work published in this blog on Spark SQL includes "Apache Spark 2.0 Performance Improvements Investigated With Flame Graphs".T
This blog post and accompanying example code have been developed in the context of the CERN IT Hadoop and Spark service.