In my previous blog post (http://db-blog.web.cern.ch/blog/szymon-skorupinski/2014-05-migrating-oracle-database-12c-what-do-auditing) I provided you with number of reasons why unified auditing looks very promising and should be seriously considered while migrating to 12c. Nonetheless, I was not talking at all about performance – which also seems to be greatly improved.
Main source of the improvement is related to the possibility of writing audit records asynchronously. It is enabled by introducing queued audit write mode, as another option to immediate write mode. The latter (not surprisingly) causes audit records to be written into the audit trail immediately. In queued write mode, which is enabled by default, audit entries are put in queue located in SGA and then persisted from there in batches. The size of this queue could be controlled by DBA, using UNIFIED_AUDIT_SGA_QUEUE_SIZE parameter (by default set to 1 MB, could be resized up to 30 MB). Drawback of this approach is the possibility of loosing some audit records kept in memory and not yet written to disk, in case of instance crash. Minimum flush threshold is configured to 3 seconds (default setting of _UNIFIED_AUDIT_FLUSH_INTERVAL parameter), but depending on database activity, flush may not happen every 3 seconds and could take longer, so in heavily loaded databases, the amount of lost audit records could be significant. The other related underscore parameter is _UNIFIED_AUDIT_FLUSH_THRESHOLD, which probably defines percentage of queue size defined by UNIFIED_AUDIT_SGA_QUEUE_SIZE, exceeding which also triggers such flush. There is also manual possibility to invoke it, by running (in this example requesting on all RAC instances):
SQL> exec dbms_audit_mgmt.flush_unified_audit_trail(dbms_audit_mgmt.flush_all_instances);
Knowing how asynchronous operations are helping to achieve better performance, I was pretty sure that performance gain would be considerable. But I’ve decided to test how big it could be. For doing that, I’ve taken 3 workloads recorded in our 11g databases and used another 12c new feature – Consolidated Database Replay, which allowed me to run all 3 workloads in parallel. They were replayed on 2-node RAC cluster, running Oracle 12.1.0.1.0 binaries, with clients running from the third machine, not to influence the results. To generate as much audit records as possible I used such an auditing policy:
SQL> create audit policy all_actions_pol actions all;SQL> audit policy all_actions_pol;
It allowed me to generate over 460 000 records per test, with less than 1% difference between them. I’ve run three tests, each lasting 1 hour, using different unified auditing settings described below:
- Immediate write mode.
- Queued write mode with UNIFIED_AUDIT_SGA_QUEUE_SIZE set to 1 MB.
- Queued write mode with UNIFIED_AUDIT_SGA_QUEUE_SIZE set to 10 MB.
Even though the number of audit records generated during each test was similar, there was a big difference in DB Time - queued write mode took around 35% less of DB Time comparing to immediate write mode. On the other hand, difference between tests with 1 and 10 MB SGA queue sizes was negligible.
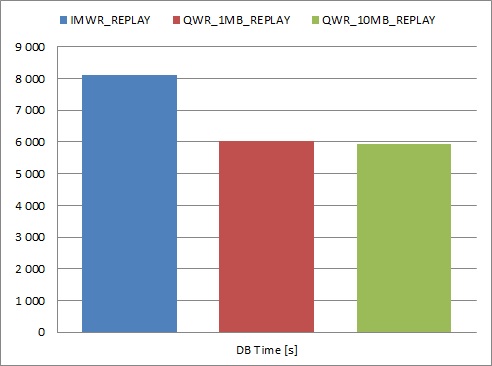
I’ve also made two additional, quite interesting observations. Please look at the graphs.
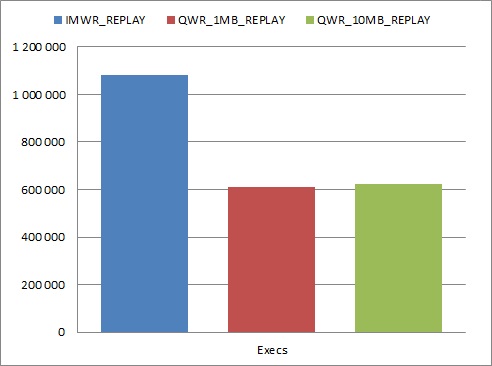
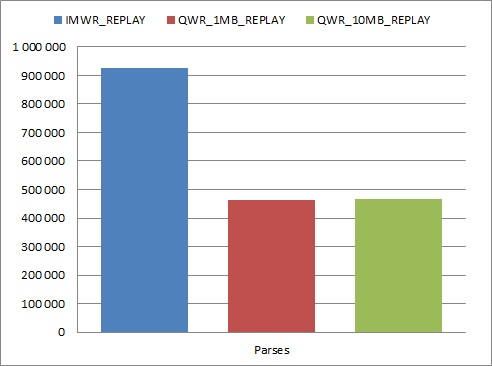
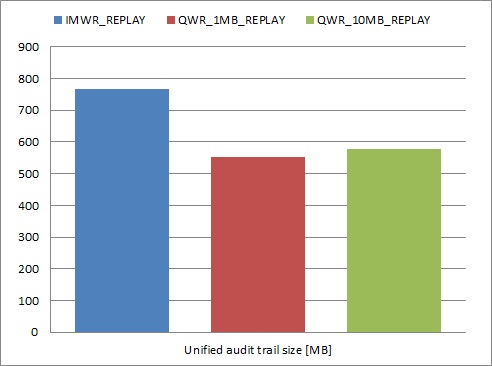
As you can see, immediate write mode caused audit segments to use over 30% more space in AUDSYS schema objects. My first suspicion is that writing audit records in bulk, causes more efficient space management than inserting one record by many different sessions in parallel.
Another observation – during test with immediate write mode, the number of parses was doubled, similar to the number of executions (around 75% increase comparing to queued write mode tests). To investigate it, I’ve run additional tests with 10046 tracing enabled. Trace files revealed two SQL statements, executed only when immediate write mode is used:
SQL ID: 2w5bgrgwvxqwy update "CLI_SWP$86b2eaec$1$1" set max_scn = :1, max_time = :2, status = :3 where rowid = :4 returning log_piece, inst_lob# into :blb, :seq SQL ID: a6r5q9yqaqabs select obj#, name, stab#, sobj#, sobjd#, ttab#, tobj#, tobjd#, mflags from rmtab$ where (stab# = :1 or ttab# = :1) order by obj#
It looks like these queries are responsible for such increase of parses and executions. Both are related to updating audit information – to confirm that the second one is also related to AUDSYS objects, I’ve looked in trace file for value of the bind used, which was 91833:
SQL> select owner || '.' || object_name obj from dba_objects where object_id = 91833; OBJ --------------------------------------------------- AUDSYS.CLI_SWP$86b2eaec$1$1
I’ve also found that RMTAB$ not exists in 11g, so probably is related to some 12c new feature. Looking in the source files located in $ORACLE_HOME/rdbms/admin, gives an idea what this could be about (taken from drep.bsq file):
-- rmtab$ - rowid mapping table (rmt) dictionary table -- a row gets added to this table when an rmt is created -- and gets deleted when an rmt is dropped.
As I’m interested in internals of unified auditing and there are still many opened questions/guesses, I encourage you to put your thoughts and suggestions in comments section. Despite my tests confirmed that it is possible to achieve significant performance gains using queued mode, before deciding on which write mode to use, you still have to answer very important question - is it acceptable to loose any of audit records in your environment?...