I have been wanting to test Apache Kafka for sometime now and finally got around to it! In this blog post I give a very short introduction on what is Kafka, installation & configuration of Kafka cluster and finally benchmarking few near real-world scenarios on OpenStack VM's
What is Apache Kafka?
Apache Kafka is a distributed publish-subscribe message broker. The core abstraction in Kafka is the topic. A topic is nothing but an append log to which producers publish their records and consumers read from it. A Kafka topic is divided into multiple partitions, these partitions are distributed across servers with in a Kafka cluster, which makes it scalable and each partition is replicated across a configurable number of servers for fault tolerance and messages in the topic are retained for a specific period of time for durability. The whole thing looks like below

You can read more about Kafka in the official documentation
Installation and Configuration
The installation is quite straightforward, you can have one broker per server (recommended) or multiple brokers per server. You also need zookeeper for the coordination of the Kafka cluster, the good news is the Zookeeper is bundled with Kafka package along with handy startup and shutdown scripts. It is also recommended to install Zookeeper outside the Kafka cluster.
Zookeeper Installation
# download and unpack the software mkdir /software cd /software curl -O http://www-eu.apache.org/dist/kafka/0.10.0.1/kafka_2.11-0.10.0.1.tgz tar xvfz kafka_2.11-0.10.0.1.tgz # change essential configuration in config/zookeeper.properties dataDir - data directory for zookeeper # start zookeeper cd $KAFKA_HOME bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
Kafka Installation
# download and unpack the software mkdir /software cd /software curl -O http://www-eu.apache.org/dist/kafka/0.10.0.1/kafka_2.11-0.10.0.1.tgz tar xvfz kafka_2.11-0.10.0.1.tgz # change essential configuration config/server.properties zookeeper.connect - points to the zookeeper; e.g host:2181 broker.id - broker id must be unique across kafka cluster; e.g 101 log.dirs - location to store the topics; e.g /kdata/logs log.retention.hours - topics retention time # start kafka cd $KAFKA_HOME $KAFKA_HOME/bin/kafka-server-start.sh -daemon config/server.properties
As you have seen its fairly easy to setup a Kafka cluster
Benchmarking Kafka on OpenStack VM's
Now that all the infra work is out of the way, let's try to run some tests to demonstrate (or more likely to understand) how Kafka works and behaves!
Test setup
Kafka cluster is running on three VM's; the spec of each VM is 4 VCPUs, 7.3 GB RAM, 100GB volume with ext4 filesystem and 10Gb ethernet
Zookeeper running on separate VM; the spec of this VM is 2 VCPUs, 3.7 GB RAM, 100GB volume with ext4 filesystem and 10Gb ethernet
I have ran the following dd commands to determine the disk throughput
[root@habench103 kafka_2.11-0.10.0.1]# dd if=/dev/zero of=/kdata/test.dd bs=100M count=100 oflag=dsync 100+0 records in 100+0 records out 10485760000 bytes (10 GB) copied, 144.381 s, 72.6 MB/s [root@habench103 kafka_2.11-0.10.0.1]# dd if=/dev/zero of=/kdata/test.dd bs=1G count=10 oflag=dsync 10+0 records in 10+0 records out 10737418240 bytes (11 GB) copied, 138.556 s, 77.5 MB/s
I have also tested with perf and it confirms that VM's have 10Gb ethernet. The following tests are run during a normal working day and repeated several times to remove any outliers.
Test1: Single producer publishing 500 byte messages with no replication
The objective of this test is to understand the scalability of Kafka cluster. I start with 1 node Kafka cluster and then add additional nodes one by one.
# create kafka topic bin/kafka-topics.sh --zookeeper habench001:2181 --create --topic test --partitions 48 --replication-factor 1 # run the producer to publish events to Kafka topic bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic test --num-records 50000000 --record-size 500 \ --throughput -1 --producer-props acks=1 bootstrap.servers=habench102:9092 buffer.memory=104857600 batch.size=9000
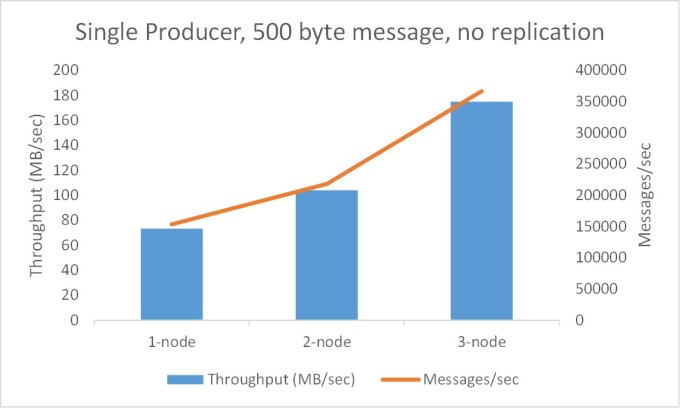
It is evident that Kafka throughput scales by adding additional nodes
Test 2: Single producer publishing 1000 byte messages with no replication
This test is repetition of the above with a different message size to understand the impact of the message size. Again I start with 1 node Kafka cluster and then add additional nodes one by one
# create kafka topic bin/kafka-topics.sh --zookeeper habench001:2181 --create --topic test --partitions 48 --replication-factor 1 # run the producer to publish events to Kafka topic bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic test --num-records 50000000 --record-size 1000 \ --throughput -1 --producer-props acks=1 bootstrap.servers=habench102:9092 buffer.memory=104857600 batch.size=9000

Again the throughput scales by adding additional nodes and larger message sizes result in higher throughput than smaller sizes which is understandable due to overhead of processing more messages.
Test 3: Single producer publishing 500 byte messages with (3x) and with out replication
The objective of this test is to understand the cost of the replication
# create kafka topic (with replication) bin/kafka-topics.sh --zookeeper habench001:2181 --create --topic testr3 --partitions 48 --replication-factor 3 # publish messages to kafka topic with required settings bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic testr3 --num-records 30000000 --record-size 500 \ --throughput -1 --producer-props acks=1 bootstrap.servers=habench101:9092 buffer.memory=104857600 batch.size=6000
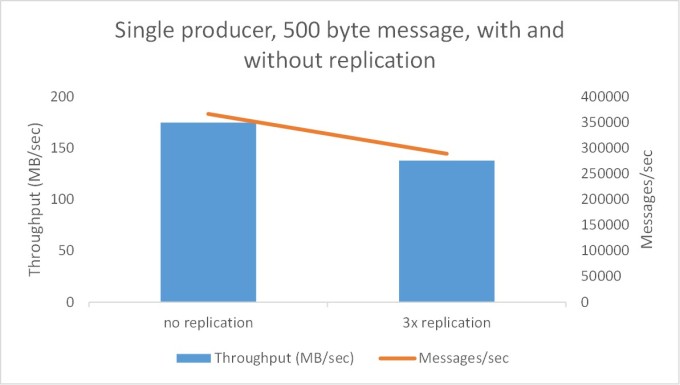
There seems to be cost involved in replicating the topic partitions, roughly about 20-25% percent. Although not bad it's worth noting that replication is not for free!
Test 4: Three producers, 3x async replication with different message sizes
The objective of this test is to understand the effect of the message size on the producer throughput
# publish 200 byte messages to kafka topic bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic testr3 --num-records 30000000 --record-size 200 \ --throughput -1 --producer-props acks=1 bootstrap.servers=habench101:9092 buffer.memory=104857600 batch.size=6000
# publish 500 byte messages to kafka topic bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic testr3 --num-records 15000000 --record-size 500 \ --throughput -1 --producer-props acks=1 bootstrap.servers=habench101:9092 buffer.memory=104857600 batch.size=6000 # publish 1000 byte messages to kafka topic bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic testr3 --num-records 10000000 --record-size 1000 \ --throughput -1 --producer-props acks=1 bootstrap.servers=habench101:9092 buffer.memory=104857600 batch.size=6000
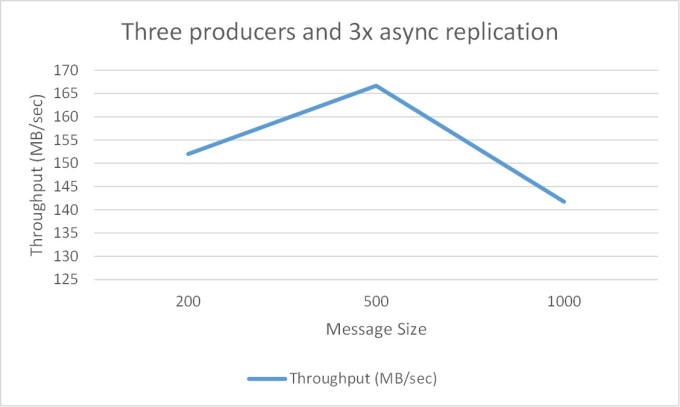
As can be seen from the above chart the throughput dropped down significantly when message size is 1000 bytes. Although this is not expected, I got the same results even after repeating the tests few times.
Test 5: Throughput with single and multiple producers
The objective of this test is see the benefits of multiple producers even when a single producer is not limited by network bandwidth.
500 byte message size and 3x async replication with single and multiple producers
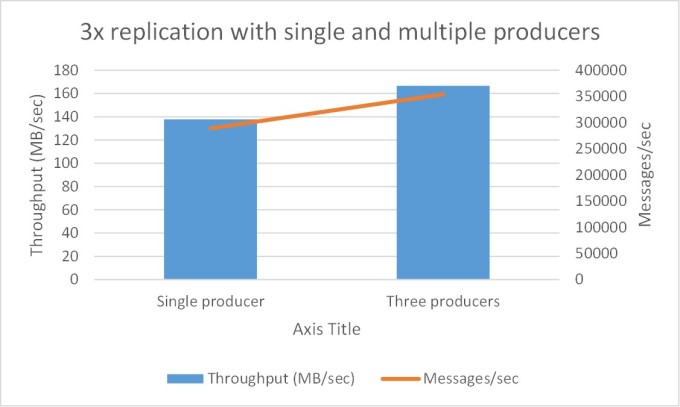
In our case, since we have 10Gb ethernet, the network throughput is not a bottleneck for single producer, however producer throughput can also be increased by adding more producers.
Test 6: Producers and Consumers in harmony
Finally in the real production deployments it is quite natural to have producers and consumers writing and reading data at the same time.
bin/kafka-run-class.sh org.apache.kafka.tools.ProducerPerformance --topic testr3 --num-records 20000000 --record-size 500 \ --throughput -1 --producer-props acks=1 bootstrap.servers=habench101:9092 buffer.memory=104857600 batch.size=6000 bin/kafka-consumer-perf-test.sh --zookeeper habench001:2181 --messages 20000000 --topic testr3 --threads 1
The result of running a combination of producers and consumers is as below| One Producer and One Consumer | Three Producers and Three Consumers | |
| Throughput | 124.47 MB/sec | 155 MB/sec |
| Messages/sec | 261038 | 330009 |
| Consumer throughput | 83.71 MB/sec | 364 MB/sec |
Learnings & Conclusion
- Number of topic partitions dearly impacts both producer and consumer throughputs.
- The message size and batch size should also be looked at, although not much can be done for the message size, the batch size should be tuned inline with the latency requirements to achieve maximum throughput.
- The producers will need in the order of couple of GB memory and the CPUs on the kafka cluster were fairly quiet.
- num.io.threads on the kafka broker can be tuned to further optimize the throughput and this again depends on the storage you have.
- The hardware requirements for the Kafka cluster are not very demanding and it seems to scale very well.