Topic: This post dives into the steps for deploying a performance dashboard for Apache Spark, using Spark metrics system instrumentation, InfluxDB and Grafana.
What problem does it solve: The dashboard can provide important insights for performance troubleshooting and online monitoring of Apache Spark workloads. In particular when running Spark applications in a distributed environment (Kubernetes, YARN, etc.).
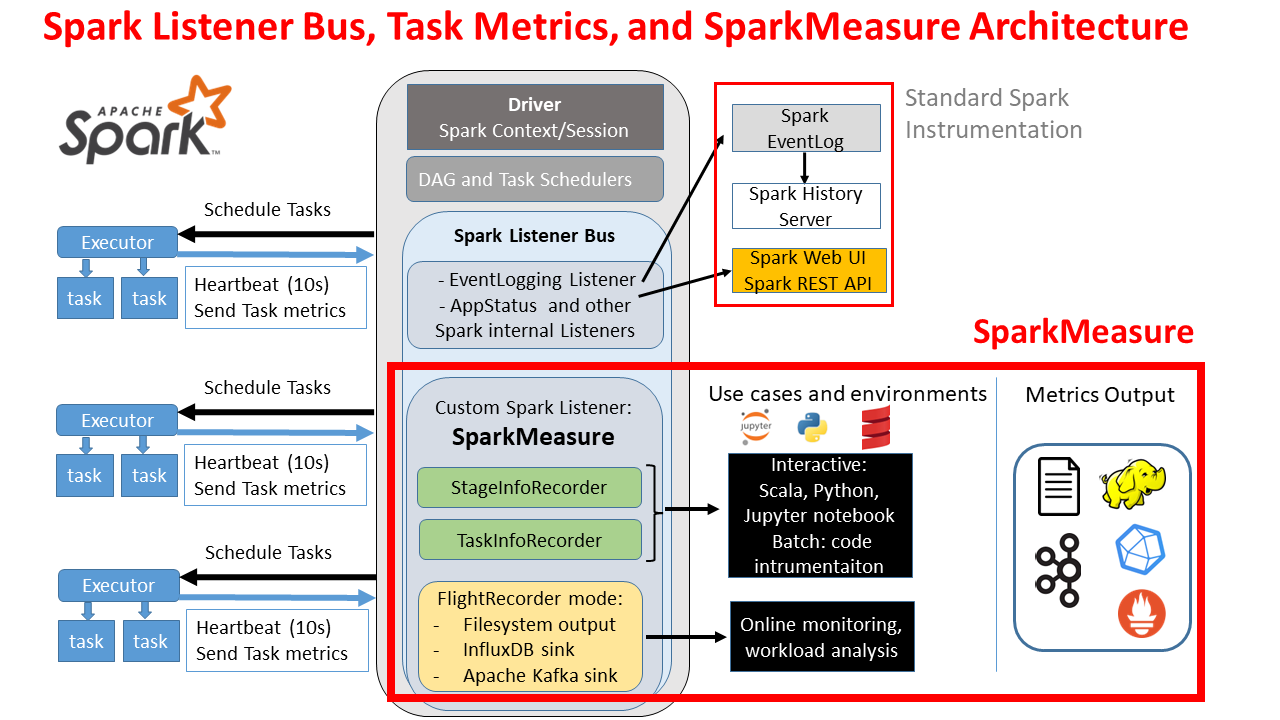
Context: Familiarity with Spark architecture and the Web UI. This discussion also overlaps with other monitoring tooling discussed in this blog, notably sparkMeasure.
This work profits of recent updates to Spark metrics instrumentation, notably SPARK-22190, SPARK-25228, SPARK-27189. It also builds on top of the ideas of previous work by Hammer Lab. Spark 3 plugins allow to extend the metrics and are useful to instrument Spark on K8S among others, see code and examples at cerndb/SparkPlugins.
Deploy the Spark Dashbord using containers: The repository spark-dashboard supports the installation of the Spark Performance Dashboard using containers technology. Two different installation options are packaged in the repository, use the one that suits your environment best:
- dockerfiles -> Docker build files for a Docker container image, use this to deploy the Spark Dashboard using Docker.
- charts -> a Helm chart for deploying the Spark Dashboard on Kubernetes.
Step 1: Understanding the architecture

Spark is instrumented with the Dropwizard/Codahale metrics library. Several components of Spark are instrumented with metrics, see also the Spark monitoring guide, notably the driver and executors components are instrumented with multiple metrics each. In addition, Spark provides various sink solutions for the metrics. This work makes use of the Spark graphite sink and utilizes InfluxDB with a Graphite endpoint to collect the metrics. Finally Grafana is used for querying InfluxDB and plotting the graphs (see architectural diagram below).
An important architectural detail of the metrics system is that the metrics are sent directly from the sources to the sink. This is important when running in distributed mode. Each Spark executor, for example, will sink directly the metrics to InfluxDB. By contrast, WebUI/Eventlog instrumentation uses the Spark Listener Bus and metrics flow through the driver in that case (see this link for further details). The number of metrics instrumenting Spark components is quite large. You can find a list of Spark metrics at this link
{kind=link}
Step 2: Configuring InfluxDB
- Download and install InfluxDB
- Note: tested in Feb 2019 with InfluxDB version 1.7.3
- Edit config file /etc/influxdb/influxdb.conf
- Enable graphite endpoint
- Key step: Configure the templates, this instructs InfluxDB on how to map data received on the graphite endpoint to the measurements and tags in the DB
- The configuration used for this work is provided at: influxDB graphite endpoint configuration snippet
- Optionally configure other InfluxDB parameters of interest as data location and retention
- Start/restart InfluxDB service: systemctl restart influxdb.service
Step 3: Configuring Grafana and prepare/import the dashboard
- Download and install Grafana
- Download the rpm from https://grafana.com/ and start Grafana service: `systemctl start grafana-server.service`
- Note: tested in Feb 2019 using Grafana 6.0.0 beta.
- Alternative: run Grafana on a Docker container
- Connect to the Grafana web interface as admin and configure
- By default: http://yourGrafanaMachine:3000
- Create a data source to connect to InfluxDB.
- Set the http URL with the correct port number, default: http://yourInfluxdbMachine:8086
- Set the InfluxDB database name: default is graphite (no password)
- Key step: Prepare the dashboard.
- To get started: download and import the example Grafana dashboard
- You can also experiment with building your dashboard or augmenting the example.
Step 4: Preparing Spark configuration to sink metrics to graphite endpoint in InfluxDB
There are a few alternative ways on how to do this, depending on your environment and preferences. One way is to set a list of configuration parameters of the type "spark.metrics.conf.xx" another is editing the file $SPARK_CONF_DIR/metrics.properties
Configuration for the metrics sink need to be available to all the components being traced, as each component will connect directly to the sink. See details at Spark_metrics_config_options Example:
$SPARK_HOME/bin/spark-shell
--conf "spark.metrics.conf.driver.sink.graphite.class"="org.apache.spark.metrics.sink.GraphiteSink"
--conf "spark.metrics.conf.executor.sink.graphite.class"="org.apache.spark.metrics.sink.GraphiteSink"
--conf "spark.metrics.conf.*.sink.graphite.host"="graphiteEndPoint_influxDB_hostName>"
--conf "spark.metrics.conf.*.sink.graphite.port"=<graphite_listening_port>
--conf "spark.metrics.conf.*.sink.graphite.period"=10
--conf "spark.metrics.conf.*.sink.graphite.unit"=seconds
--conf "spark.metrics.conf.*.sink.graphite.prefix"="lucatest"
--conf "spark.metrics.conf.*.source.jvm.class"="org.apache.spark.metrics.source.JvmSource"
Step 5: Test/understand the metrics for performance troubleshooting
The configuration is finished, now you are ready to test the dashboard. Run Spark using the configuration as in Step 4 and start a test workload. Open the web page of the Grafana dashboard:
-
A drop-down list should appear on top left of the dashboard page, select the application you want to monitor. Metrics related to the selected application should start being populated as time and workload progresses.
-
If you use the dashboard to measure a workload that has already been running for some time, note to set the Grafana time range selector (top right of the dashboard) to a suitable time window
-
For best results test this using Spark 2.4.0 or higher (note Spark 2.3.x will also work, but it will not populate executor JVM CPU)
- Avoid local mode and use Spark with a cluster manager (for example YARN or Kubernetes) when testing this. Most of the interesting metrics are in the executor source, which is not populated in local mode (up to Spark 2.4.0 included).
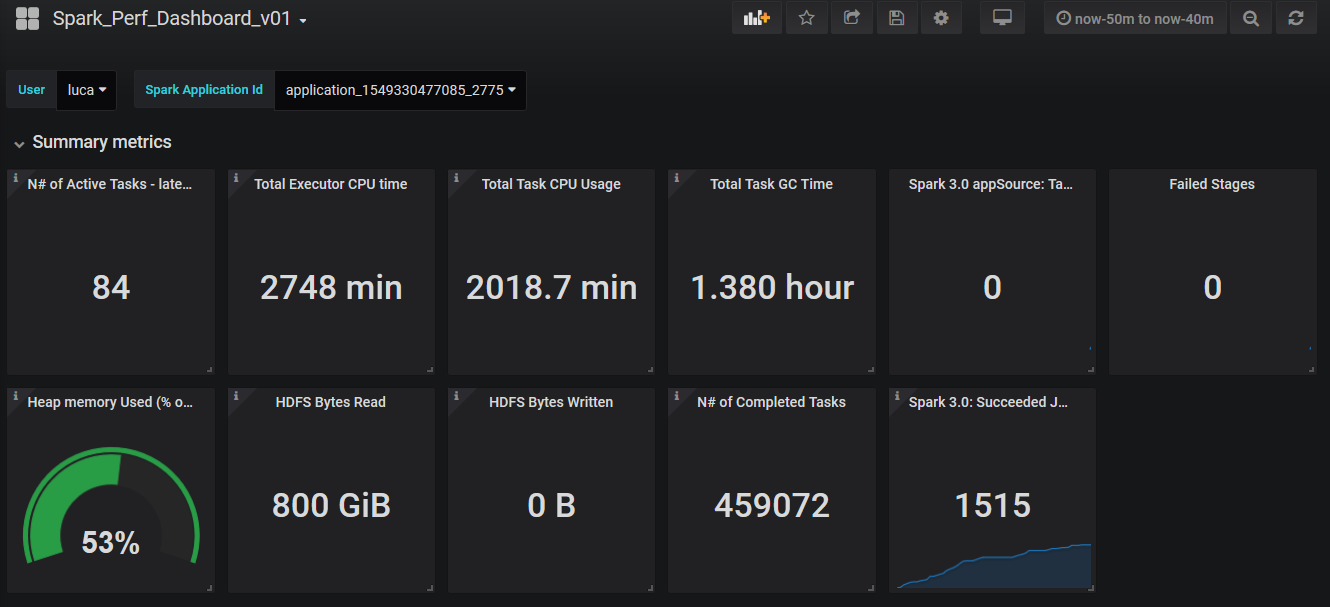
Dashboard view: The following links show an example and general overview of the example dashboard, measuring a test workload. You can find there a large number of graphs and gauges, however, this is still a selection of the many available metrics in Spark instrumentation.The test workload is Spark TPCDS benchmark at scale 100 GB, running on a test YARN cluster, using 24 executors, with 5 cores and 12 GB of RAM each.
- Dashboard part 1: Summary metrics
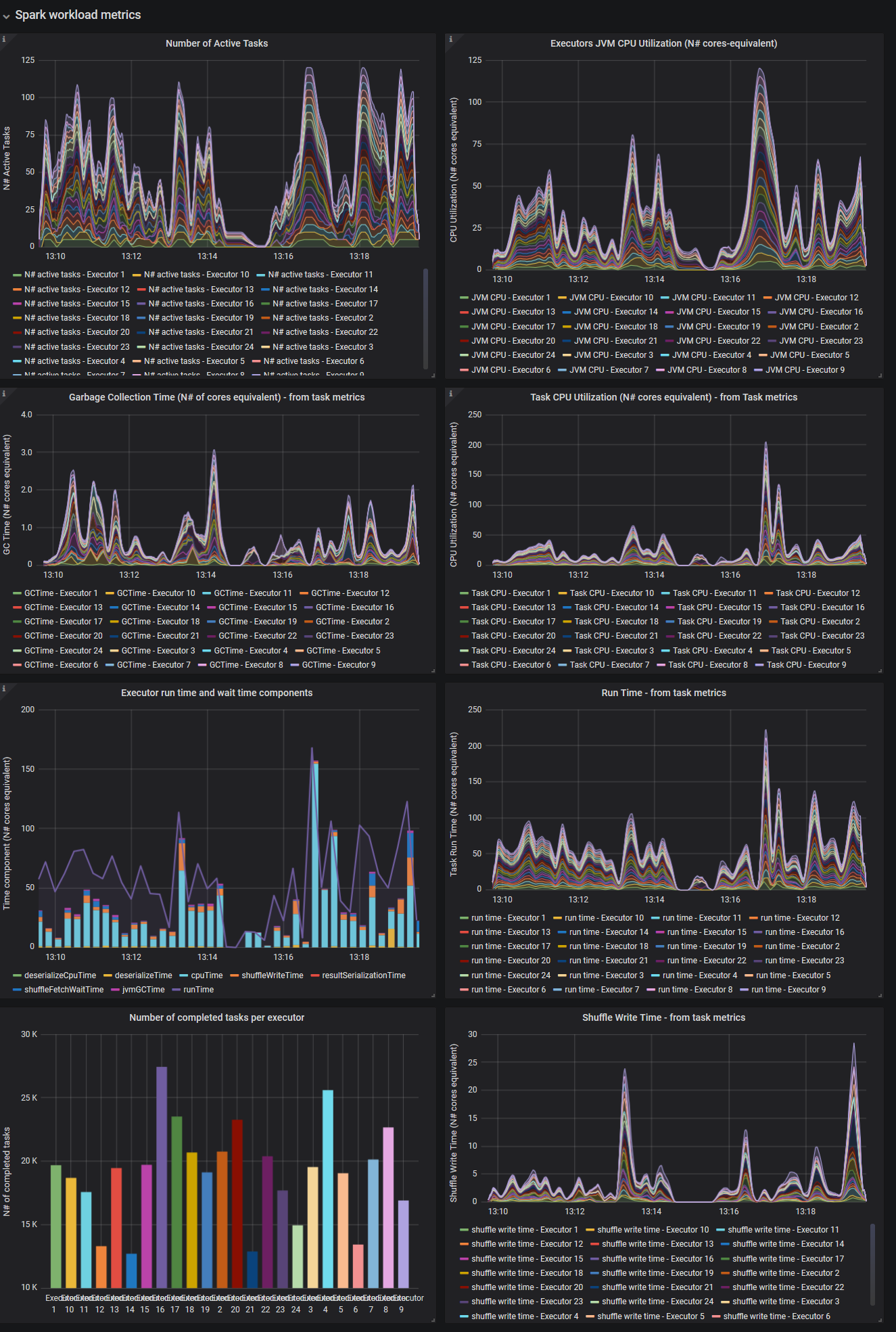
- Part 2: Workload metrics
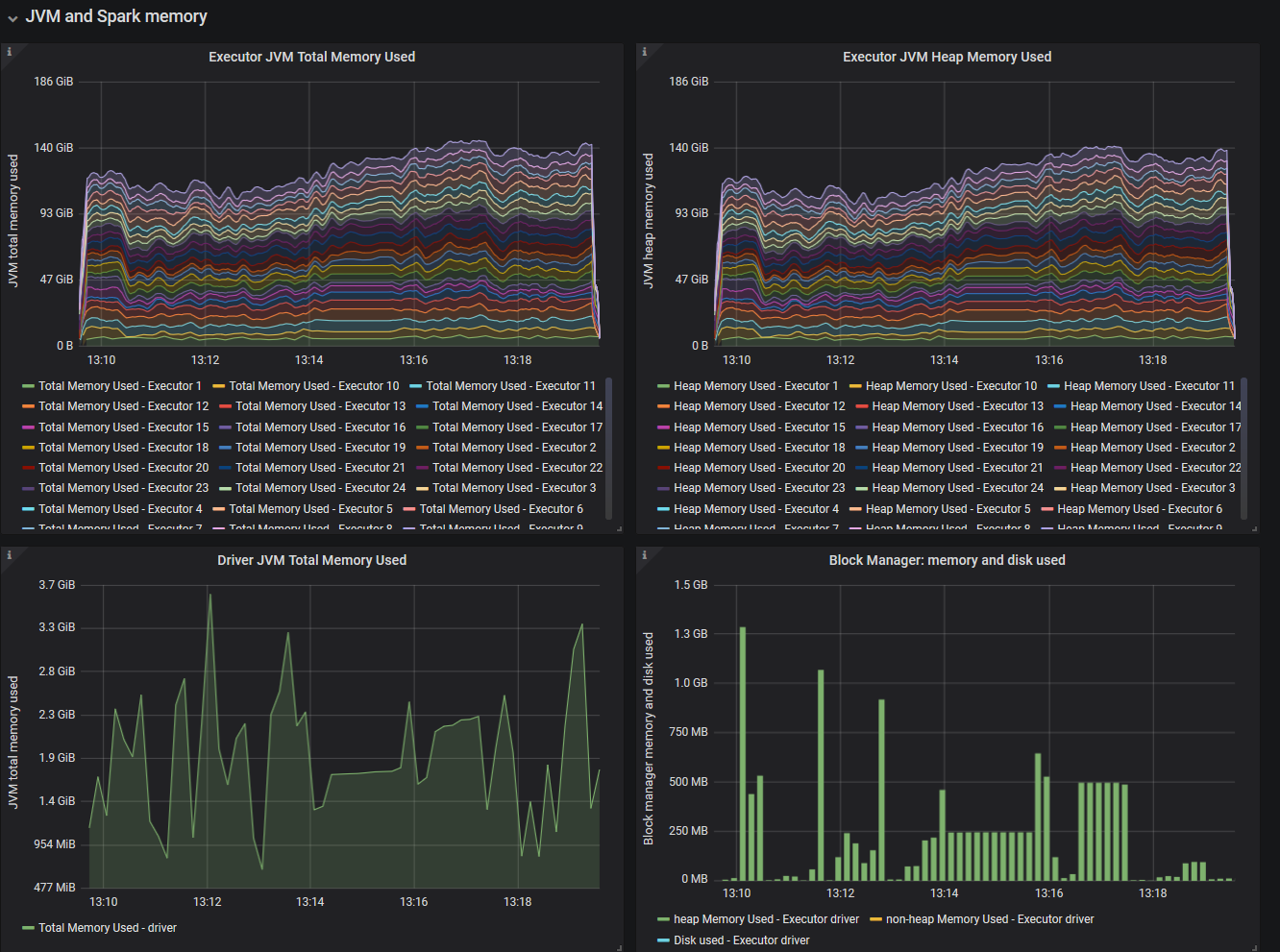
- Part 3: Memory metrics
- Part 4: I/O metrics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Example Graphs
The next step is to further drill down in understanding Spark metrics, the dashboard graphs and in general investigate how the dashboard can help you troubleshoot your application performance. One way to start is to run a simple workload that you can understand and reproduce. In the following you will find example graphs from a simple Spark SQL query reading a Parquet table from HDFS.
- The query used is
spark.sql("select * from web_sales where ws_list_price=10.123456").show web_salesis a 1.3 TB table from the Spark TPCDS benchmark](https://github.com/databricks/spark-sql-perf) generated at scale 10000 GB.- What the query does is reading the entire table, applying the given filter and finally returning an empty result set. This query is used as a "trick to the Spark engine" to force a full read of the table and intentionally avoiding optimization, like Parquet filter pushdown.
- This follows the discussion of Diving into Spark and Parquet Workloads, by Example
- Infrastructure and resources allocated: the Spark Session ran on a test YARN cluster, using 24 executors, with 5 cores and 12 GB of RAM each.
Graph: Number of Active Tasks

One key metric when troubleshooting distributed workloads is the graph of the number of active sessions as a function of time. This shows how Spark is able to make use of the available cores allocated by the executors.
Graph: JVM CPU Usage

CPU used by the executors is another key metric to understand the workload. The dashboard also reports the CPU consumed by tasks, the difference is that the CPU consumed by the JVM includes for example of the CPU used by Garbage collection and more.
Garbage collection can take an important amount of time, in particular when processing large amounts of data as in this case, see Graph: JVM Garbage Collection Time
{kind=link}
{kind=link}
Graph: Time components

Decomposing the run time in component run time and/or wait time can be of help to pinpoint the bottlenecks. In this graph you can see that CPU time and Garbage collection are important components of the workload. A large component of time, between the "executor run time" and the sum of "cpu time and GC time" is not instrumented. From previous studies and by knowing the workload, we can take the educated guess that this is the read time. See also the discussion at Diving into Spark and Parquet Workloads, by Example
Graph: HDFS read throughput

Reading from HDFS is an important part of this workload. In this graph you can see the measured throughput using HDFS instrumentation exported via the Spark metrics system into the dashboard.
Lessons learned
- The dashboard provides many useful insights on Spark workload:
- It allows to measure and visualize the time profile of resource utilization, starting from the number of concurrent tasks, to CPU, I/O and shuffle metrics.
- Additional info is provided on time spent (or time waited) by Spark workload per component.
- The most useful metrics for the cases I used Spark performance dashboard appear to come from the executor source.
- Understanding the dashboard graphs is still the domain of the dashboard user/performance analysis.
- The dashboard does not directly provide root cause analysis, nor finds bottlenecks. However it helps the user to do that.
- The dashboard is only as good as the metrics that feed it. Interference can have many forms, for example when running on highly-loaded systems.
- This work is still experimental. For example we noticed that in certain cases metric values seem wrong and/or hard to understand (see also issues with task executor metrics described below)
- Spark task executor metrics contain very important information, but come with additional complexity
- Task metrics are cumulative, which means that for many graphs you want to compute deltas, for example with InfluxQL this can be done with the function non_negative_derivative.
- Task metrics values are incremented only at the end of each task. This may create an issue that affects workload graphs of jobs where task duration is greater than metric data input rate. As a workaround, tune spark.metrics.conf.*.sink.graphite.period (the suggested value in Step 2 is to set this to 10s).
- Task metrics are updated only for successful tasks. Workload metrics of failed tasks are not visible in the task metrics graphs.
- Templates for the graphite endpoint of InfluxDB are very important
- Templates allow to structure incoming metrics data into InfluxDB tables.
- The proposed template values in the example have been set up by experimentation, they are still being developed: see details in Step 2 and in particular InfluxDB graphite endpoint configuration snippet.
- There are many areas in which this work can be improved both on the Apache Spark side and the metrics collection/visualization side. Some random notes on this:
- Annotations linking Spark job information with metrics with job information would be useful to help drilling down on the workload. This for example on how to answer questions like: "I see an increase in CPU usage at time XX, which query/job/stage caused that?" (note added, this has been since addressed, see this link).
- Many components of the time spent/time waited are not directly instrumented in Apache Spark yet: think I/O read time. Also time and resources consumed outside the JVM (for example by Python UDF) are not instrumented
- The Graphite endpoint does not use a password. It would be advisable to have a full InfluxDB sink in Apache Spark, including full credential connectivity support, rather than using the graphite endpoint.
CERN Spark service experience
- We have installed and provide a shared dashboard as an experimental offering to the users of CERN Spark service (both for Spark on YARN/Hadoop and Spark on Kubernetes).
- We have worked with Spark community to push a few improvements to the instrumentation, as discussed here, in particular exposing Spark task metrics with the Dropwizard metrics system: SPARK-22190, SPARK-25228, SPARK-25277, SPARK-26890
- We have also used the dashboard in the context of a project for data analysis at scale (up to 800 concurrent cores). In that context we have also introduced custom instrumentation/metrics to Spark and the monitoring dashboard, which has proved to be easily extensible and customizable.
Conclusions
You find in this post the details of how to build a performance dashboard for Apache Spark workloads. The dashboard can provide important insights for performance troubleshooting and real-time monitoring of Apache Spark workloads. The implementation on Spark metrics system integrated with InfluxDB and Grafana. In addition you can find links to details of the available metrics instrumentation, configuration details for InfluxDB and examples of Grafana dashboard and graphs that you can use as a starting point for further exploration.
We wish you a fruitful time monitoring and troubleshooting Spark, if you find some mistakes of good additions to the dashboard that you want to share, we will be happy to hear from you.
Acknowledgments: this work has been developed in the context of the data analytics services with Apache Spark, Hadoop and streaming at CERN IT, thanks to the collaboration of several colleagues in the teams. Contacts for questions about this work: Luca.Canali@cern.ch and Prasanth.Kothuri@cern.ch
Hi, Thank you very much for the detail step by step guide, however, while going through the instruction, I dont see any installation recommendation for Graphite, do we need to install Graphite tool to enable graphite protocol you specified in the spark configuration file? Without installing Graphite, will InfluxDB listen to the port 2003 you suggested?
Hi Prashun,
Thanks for your interest in this. You don't need to install Graphite. You can follow the instructions linked in the blog entry to configure a graphite endpoint using InfluxDB directly.
Hi,
As a data engineer, I'm currently working on a similar project using Prometheus sink. Monitoring Spark on cluster is crucial.
Thank you for a such a clear and concise post.
Best regards
Thanks for work, it really helped a lot.
In the Spark workload metrics dashboard, ratios of which metrics should we consider to plot the executor jvm cpu utilisation and task cpu utilisation