Introduction
While working on a data set it is important that it stays easily and quickly accessible. Hibernate second-level caching with Coherence offers applications a resource optimized solution that keeps frequently used data in memory, by distributing it among different application instances, or sharing it with one or more dedicated cache machines. This article describes the knowledge that we gained through using the Oracle Coherence Community Edition for Hibernate second-level caching and gives a general overview of how this product can be used with Java applications running on Kubernetes.
Author: Viktor Kozlovszky
1. Architectural overview
In mid-2020 Oracle released a community edition of their Oracle Coherence product. This open-source product offers an easy way to connect multiple instances together and allows them to form a cluster. The product can be built in as a standard third party module (such as for Hibernate second-level caching) or run as an independent Coherence instance. In the infrastructure it can take one of two roles, it can act either as a cache server or as a client that uses the cache server.
To see how this technical solution would work within our infrastructure and function as a second level cache for Hibernate applications, we decided to test it with a Java application that runs on Kubernetes. For this application, we added Coherence as a dependency package and configured it to act as a client. We spun up the client instances in a Kubernetes cluster (“Application K8s cluster”) and linked them with another Kubernetes cluster where the cache server cluster (“Coherence K8s distributed cache cluster”) was running. Figure 1.1 shows the components used for the evaluation.
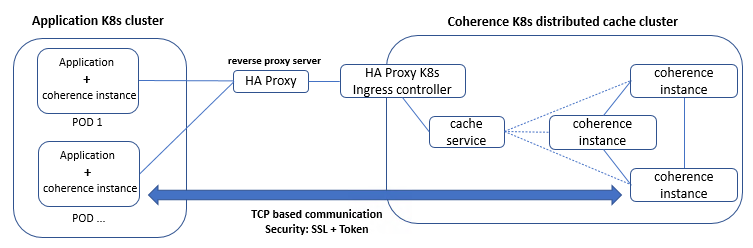
Figure 1.1 Component overview of the test use case.
The exercise showed us that Coherence relies on TCP/IP protocol for communication among its member instances. This information is crucial from an infrastructure perspective because it determines what infrastructure components can be used for building a stable production system.
Coherence offers different architecture design and supports a variety of TCP connectors for linking the instances together. Based on our work, we have the following practical advice for use cases when the cache servers and clients are contained in separate Kubernetes clusters:
- It is best if the Coherence clients are designed as Coherence*Extend clients. This is because these clients do not require direct interaction with other cluster members, therefore they can live on different subnets of the network.
- In a Kubernetes environment to ensure that the expansion of an existing Kubernetes cluster by a new node machine or the replacement of an existing node machine stays simple, a proxy server introduction is recommended between the two Kubernetes environments. Using this approach, the clients will use the proxy URL and the proxy server will take care of forwarding the traffic to the right endpoints. It’s important to keep in mind that when selecting the proxy solution, it will only do port forwarding on TCP level.
- It is possible to use SSL for securing the communication between the instances, however if the traffic goes through these proxy servers it’s important that they support TCP level SSL termination or redirection.
- Instead of directly exposing a Kubernetes service, the common practice is to channel the traffic through an ingress controller. Since the communication between the client and server is happening on TCP level (communication relies only on IP and the port, instead of HTTP headers), our recommendation is to use a dedicated ingress controller for the Coherence Kubernetes service.
The direct TCP level based communication aspect also plays an important role when aiming for a highly available cache cluster service. The best Kubernetes design for such community edition clusters is to have a separate Kubernetes cluster for the cache servers where the node machines are in different availability zones. This design will prevent service downtime.
At the time of writing Oracle recommends having a separate Coherence cluster for Hibernate application. This recommendation comes, because Hibernate‘s second-level cache uses a separate cache (Map) for each class of object, which are mapped by Hibernate; and Oracle Coherence replicates these Maps on the cache server side without linking them to an application.. This means that when different applications have the same object class names, errors can arise as one application might not have the same attributes as the other therefore the stored data will end up missing essential information. There is a static workaround for this, which is to dedicate separate cache services in the cache configuration for the different applications and design internal coherence proxy services that are responsible for writing data to the right cache service. The static workaround in this context means that to share a Coherence cluster with a new application using Hibernate, the cache configuration needs editing and the whole cache cluster needs restarting.
2. Object caching
Coherence can work with data that is produced by the application or with data that is being retrieved from a database. For implementing a second-level cache for Hibernate, Oracle provides a project named Coherence-hibernate. Since different Hibernate versions have major changes in their second-level cache design, therefore Oracle provides version dedicated modules. The following considerations are important when it comes to making these work (see Figure 2.1 for reference):
- On the client side it’s necessary to add the Coherence-hibernate library, setting the Coherence-hibernate application properties, and adding the Hibernate object annotations.
- On the server side, it’s necessary to include the corresponding versions of the Hibernate-core and Coherence-hibernate libraries as well as the Jakarta-persistence-api library.
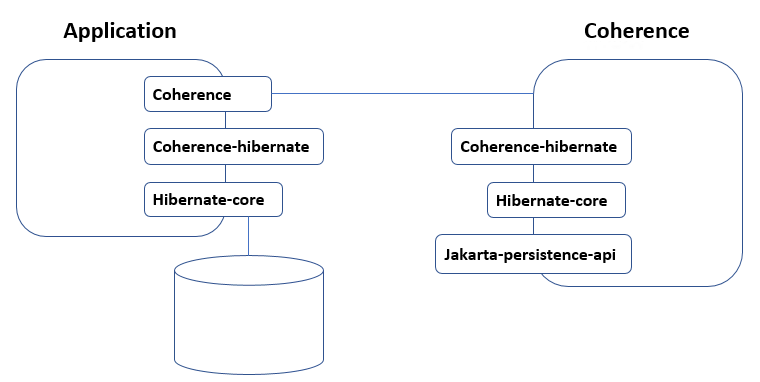
Figure 2.1 Components for hibernate object caching.
As mentioned earlier Coherence can store not only Hibernate objects, but other custom Java objects as well following a key-value pair cache approach. The latter case is independent of Hibernate and does not require the Coherence-hibernate module. For these custom objects Coherence offers the possibility to fine tune and optimize cache usage and allows object pre-processing on the server side. This can be done using Portable Object Format (POF), which allows for custom objects to diverge from the default Java serialization. It’s important to note that POF objects and cache server side search and aggregation tasks, require custom object definitions on both the server and the client side.
3. Security
Based on our work, we have identified the following possibilities from a security perspective using the Coherence Community edition:
- Instances need to meet the member identity criteria in order to interact with each other. In the absence of the right identity the instance will be rejected.
- With some performance drawbacks communication can happen on SSL between cluster members (i.e. between two servers and between client and server).
- Coherence offers the possibility to include self-developed custom security libraries. Using these an identity token is introduced into the client-server message handling. Thanks to the custom classes the token generation and revision can support a range of authentication methods.
- It is possible to restrict member access through IP filtering.
- For Coherence*Extend clients there is additional security involved, because the clients are connecting to an internal Coherence service first (i.e. the Coherence proxy service) and through that they interact with the cache services. For this reason, the service names must match on both the client and the server side, otherwise the connection attempt will be refused.
4. Deploying to Kubernetes
Oracle provides a Kubernetes operator for Coherence that helps to deploy the Coherence cache cluster in a simple way. The operator supports the deployment of custom Coherence images. It’s important to note that the custom entry points of the image will be disabled on the running instances deployed by the operator. There is a vast amount of information on the Coherence operator page, regarding how to design a custom image and there is also an article on how to run a Coherence cluster in Docker. It is recommended that the operator is used for deploying at least the server side and the Kubernetes service which is used for the cache cluster, because the operator will handle most of the complex configurations.
For production systems, we recommend the use of an Ingress controller that channels the traffic to the Coherence K8s service. This dedicated controller is needed because the communication is on TCP level, therefore there are no HTTP headers which would allow traffic to be shared among different Kubernetes services. For SSL communication, selecting an ingress controller that supports SSL termination and redirecting is essential.
5. Instance configuration
Getting the instance configuration correct is a very important step of the process. The Coherence configuration can be categorized into two major parts, which can be broken down into two different files.
- The first file contains all the instance related settings that are essential for cluster member identification, as well as the configuration fields for the communication approach used by the instances. Note, that when the clients are configured to be an active member of the cache cluster they should be on the same network.
- Cluster members can communicate with each other using unicast or multicast messaging. The default setting for communication is multicast with one fixed and one dynamic port. Multicast communication builds on the fact that the instances are sharing the same network, but since each individual Kubernetes platform has its own network, therefore the network won’t be shared and unicast communication suits better. In order to switch from multicast to unicast the (two) unicast ports and at least one server member need to be defined as a WKA (Well Known Addresses). In addition to the multicast and unicast ports Coherence uses the TCP port 7 for checking the health state of the cluster members.
- The second file configures the cache storage. It’s possible to have different types of local storages as well as remote storage. These are called cache schemas. The clients that are interacting with the cache cluster through a remote schema are called Coherence*Extend clients. These clients are part of the cluster, but their health status is not checked. Except for the cluster membership identification fields these clients can be implemented with their default settings. However, it is worth configuring them to run as unicast because otherwise they will pollute the network with discovery messages. Extend clients as described earlier will connect to a Coherence internal proxy service first, which will ensure that the right storage is used. For our tests we used this Coherence*Extend client approach.
Finally, it’s important to note in regards to configuration, that Coherence loads the default settings first and then overwrites them with custom settings, therefore for the fields that are not defined, default settings will be used.
6. Conclusions
This article was intended to provide a high-level overview of what can be achieved and what to pay attention to when working with Coherence as a Hibernate second level cache provider using the community edition of Coherence. Starting from architecture design we touched on the possibilities for storing objects, the options available for securing our cache system, what can be used for deploying to Kubernetes and how we might start thinking about configuration. Oracle’s current recommendation is to dedicate one cache cluster for one kind of application to prevent cached object corruption. We discussed that the product uses TCP/IP protocol for communication among its cluster members. We also explained that for production systems the introduction of a proxy server and ingress controller is highly recommended, especially in cases where the client and server are contained within different Kubernetes clusters. Finally, we mentioned that in the selection process for those two components, it’s important to consider TCP level support for traffic forwarding and SSL.
Overall, the community edition of Coherence seems to be a good candidate for large, complex applications that need to keep a substantial amount of data in the application cache. The product allows us to apply data preparation logic on the cache server side, which can simplify and boost business logic execution.
7. Component references
- Oracle Coherence Community Edition (https://coherence.community/)
- Oracle Coherence Operator (https://github.com/oracle/coherence-operator)
- Oracle Coherence Hibernate (https://hibernate.coherence.community)
- HAProxy (https://www.haproxy.com/)
- HAProxy Ingress Controller (https://www.haproxy.com/documentation/kubernetes/)